

TL;DR: What this guide covers and the bottom line
-
Run the developer implementation flow in this guide to add consent and fallbacks.
-
Use the compliance checklist to map responsibilities and residual risks.
-
Pilot with a short trial and request an enterprise review before scaling.
Why text-to-speech matters for accessibility (and SEO/business benefits)
Who relies on TTS
-
People with vision loss who use screen readers or audio interfaces.
-
People with dyslexia and other reading disorders benefit from read-aloud support.
-
Non-native speakers or low-literacy audiences who prefer listening.
-
Users with cognitive or attention differences who process audio better.
Business and SEO benefits
-
Higher engagement: users spend more time when audio is available.
-
Broader reach: content serves low-literacy and non-native audiences.
-
SEO upside: richer content formats can improve indexing and dwell time.
-
Risk reduction: accessible options help meet WCAG standards and legal expectations.
Accessibility vs Privacy: core tensions and real risks
Key risks to evaluate
-
Misattribution and impersonation. A cloned voice can be used to impersonate someone, harming reputation and safety.
-
Unauthorized reuse. Audio created for accessibility can be copied and used in ads or political messaging.
-
Data exposure. Raw voice samples and transcripts are personal data that can leak if not secured.
-
Deepfake-enabled fraud. High-quality synthetic voices can aid scams or identity theft.
-
Emotional or psychological harm. Hearing a familiar voice in harmful content can distress users.
Legal and reputational checklist
How DupDub balances accessibility and privacy (product-focused overview)
Designed for real accessibility outcomes
-
Natural-sounding multilingual TTS with emotion and style options
-
Voice cloning is restricted to the original speaker to ensure consent
-
Automatic transcription and subtitle alignment for screen readers and captions
-
Avatars and photo-to-video tools for contextual audio/visual content
Privacy, your regulatory team will appreciate
-
Encryption at rest and in transit protects sensitive data
-
Consent controls and retention rules ensure responsible data use
-
Role-based access, audit logs, and secure API keys allow admin teams to manage voice cloning and content creation securely
-
Ownership lock on cloned voices
-
Access control enforcement
-
Consent workflow fallback behavior
-
Export and retention policies
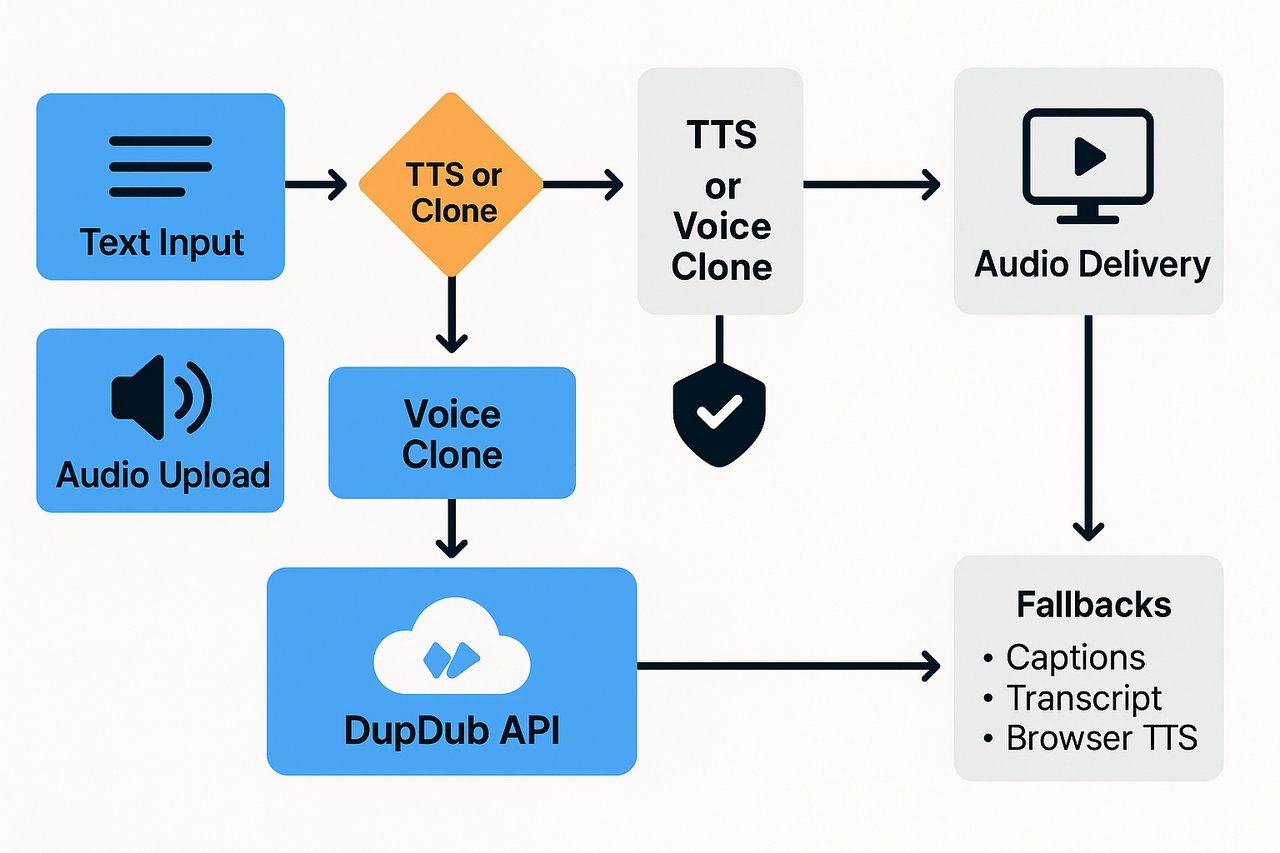
Step-by-step implementation guide for developers
Architecture overview: keep components simple
DupDub API integration tips
-
Use server-side API keys only, never embed keys in the browser. Rotate keys and limit scopes.
-
Start with async jobs: request generation, poll status, then fetch the URL. Webhooks are better for scale.
-
Pick a voice by ID and pass locale, style, and speech rate. Test with short samples first.
-
Store only what you need: keep transcripts, not raw audio, unless the user consents. Encrypt stored artifacts.
Consent and voice-cloning opt-in flow
-
Show clear consent UI before collecting voice samples. Explain use, storage, and sharing.
-
Record a short sample, upload it to the server, and call DupDub's cloning endpoint.
-
Require an explicit checkbox and a time-stamped consent record.
-
Let users revoke and request deletion. Treat cloned voices as user data and lock them to the original speaker.
Accessible fallback patterns for progressive enhancement
-
Always surface a synced transcript and captions.
-
Use browser SpeechSynthesis as an offline fallback.
-
Provide a slow playback and volume control UI.
-
Offer a one-click download of the transcript and audio.
Sprint-ready task list
-
Design consent screens and captions UI.
-
Implement server endpoints, secure DupDub keys, and webhook handlers.
-
Add client audio player, keyboard controls, and transcript view.
-
Run accessibility tests, privacy review, and opt-in audits.
Compliance checklist & risk assessment for teams
WCAG checkpoints
-
Mark pronunciation for ambiguous words, supporting comprehension for assistive users.
-
Provide captions, synced transcripts, and readable labels.
-
Ensure keyboard control, focus management, and clear play/pause controls.
-
Offer adjustable voice, speed, and volume options.
Privacy, consent, and retention
-
Get explicit, recorded consent for voice cloning and recordings.
-
Limit data collection to needed fields only.
-
Define short retention windows and default deletion rules.
-
Allow users to revoke consent and trigger deletion.
Audit logging and documentation
-
Record consent events, model inputs, and deletion actions.
-
Maintain a data processing record and DPIA for legal review.
-
Attach test logs showing TTS accessibility checks.
Quick risk rating
Vendor comparison: DupDub vs common alternatives (accessibility & privacy lens)
Quick comparison table
|
Criteria
|
DupDub
|
Common alternatives
|
|
Voices & languages
|
700+ voices, 90+ languages; 1,000+ styles
|
Varies: some offer many voices, fewer languages, or styles
|
|
Consent & voice-clone controls
|
Cloning locked to original speaker; explicit sample requirement
|
Often allow cloning, but policies and locks vary by vendor
|
|
Encryption & data handling
|
Encrypted processing; data not shared with third parties
|
Mixed: some encrypt, some use third-party models or analytics
|
|
Accessibility features
|
SRT alignment, subtitle generation, avatar captioning, API for fallback
|
Feature sets differ; not all include subtitle alignment or avatar captions
|
How to pick: action-first guidance
-
Match access needs. If you must support captions, multi-language dubbing, and avatar captions, prefer vendors with built-in SRT alignment and subtitle export.
-
Verify cloning controls. For enterprise or user-clone scenarios, require sample-locking and explicit consent logs.
-
Audit data flows. Ask vendors for encryption at rest and in transit, retention windows, and third-party sharing rules.
-
Test fallbacks. Ensure an accessible fallback (human-readable captions or default voice) if synthetic audio fails.
Troubleshooting common text-to-speech accessibility issues
Mispronunciation: check voice, lexicons, and SSML
-
Add phonetic hints using SSML (Speech Synthesis Markup Language) or phoneme tags.
-
Build a site lexicon for brand names and acronyms and feed it to the TTS engine.
-
Try an alternate voice if a voice model mispronounces a language.
Sync and reading-order errors: validate DOM and ARIA
-
Ensure DOM order matches visual order and use ARIA landmarks for structure.
-
Use explicit timing or subtitle cues from the TTS API when available.
-
Provide a simple text fallback for users who prefer reading.
Stuttering and audio glitches: isolate buffering and encoding
-
Use chunked streaming or smaller audio segments.
-
Normalize audio levels and prebuffer short clips before playback.
-
Fallback to server-side rendered audio for unstable clients.
Mobile bandwidth and large files: optimize delivery
-
Offer lower bitrate or compressed MP3 alternatives.
-
Lazy-load voices and stream rather than download full files.
-
Provide a lightweight text-only mode for low-bandwidth users.
FAQ — Practical answers to common questions
-
Does accessibility text-to-speech satisfy WCAG requirements?
TTS can help you meet WCAG by providing an alternative way to consume text. It must be paired with semantic HTML, keyboard controls, visible play/pause/stop, and captions where audio conveys information. Test with screen readers and real users to confirm it improves access.
-
Is voice cloning legal, and what are consent best practices for voice cloning?
Legality depends on jurisdiction and use. Best practice is explicit, informed consent: a signed or recorded agreement that explains the use, sharing, retention, and commercial rights. Verify identity, age, and scope. Keep consent records and let speakers revoke permission.
-
How do I capture opt-ins for voice cloning and TTS usage?
Use clear, separate opt-ins, never bundling consent with terms. Options: - Checkbox with short purpose text - Recorded verbal consent saved to logs - Email confirmation for long-term use Log timestamp, IP, and consent text. Offer a one-click revoke and a contact for questions.
-
What are the performance and cost tradeoffs for TTS implementations?
Pre-rendering audio saves cost and lowers latency, but is less flexible. Real-time streaming gives personalization and lower storage needs, but higher compute cost and small delays. Higher-quality voices use more credits or compute. Choose based on scale, latency needs, and budget.
-
What records and processes help with compliance audits for TTS and voice cloning?
Keep consent logs, Data Protection Impact Assessments, vendor contracts, encryption and retention policies, and an access audit trail. Include a breach response plan and periodic reviews.
 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook