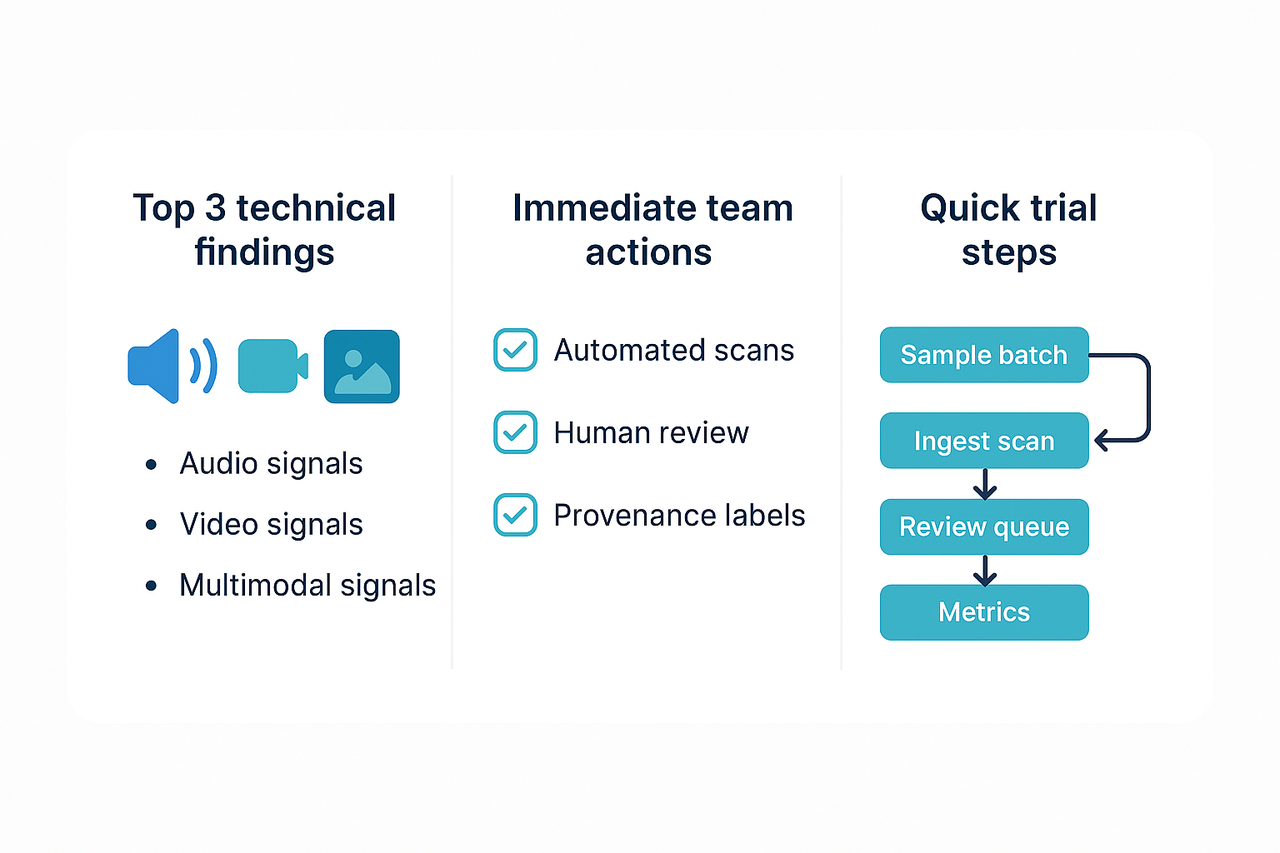
TL;DR: Key takeaways
Deepfake detection techniques now work best when they use both audio and visual cues together. Modern methods spot mismatches in voice, lip motion, and metadata, so teams should assume single-signal checks miss clever fakes.
Quick actions for teams: run automated scans on new uploads, add a lightweight human review step for flagged content, and apply visible provenance labels (watermarks or metadata tags). Also, keep a small test set of known good and fake files for ongoing calibration.
Trial steps to validate a workflow: pick a small content batch, run detection at ingest, route high-risk items to review, and measure false positives weekly. Start simple, tune thresholds, and log decisions so you can audit results and improve models.
Why deepfakes matter for voice cloning, localization and brand safety
As voice cloning and AI dubbing scale, the chance of misuse also rises, and teams must respond. Modern creators and localization leads now need to understand deepfake detection techniques to keep content and audiences safe. This section explains the practical risks, with an eye toward compliance and product decisions.
Immediate risks for creators and brands
Deepfakes can damage trust fast. A fake voice can impersonate a spokesperson, spread false claims, or seed misinformation. For creators, a single viral clip can harm reputation and viewership. For brands, the cost can show up as lost customers, bad press, and legal exposure.
Common threat scenarios
-
Impersonation of spokespeople or influencers, used in scams or false endorsements.
-
Unauthorized localization that misstates claims or regulatory language.
-
Deepfake audio in training or compliance materials creates safety gaps.
-
Brand hijacking, where ads or promos run with an altered voice.
Operational and legal exposure
Regulators and platforms have begun to act. That raises the stakes for teams that publish dubbed content. Compliance officers must track consent, recordkeeping, and disclosure rules. Product leads must weigh voice cloning benefits against audit and retention needs.
Companies face both civil risk and platform takedowns. They also risk automated moderation flags that reduce reach. These outcomes make the business case for detection, logging, and rapid takedown workflows.
Why localization teams should care
Localization is a growth tool, but it can spread risk globally. A badly labeled or cloned voice can violate local ad rules, copyright, or privacy laws. Content ops and legal teams should bake detection into review gates. That keeps creative speed without sacrificing safety.
From policy to practice
Make detection operational, not optional. Combine automated screening, human review, and immutable consent records. Log detected incidents, flag high-risk clips, and add approval steps for cloned voices. With those controls, teams can use voice cloning while managing brand safety and legal exposure.
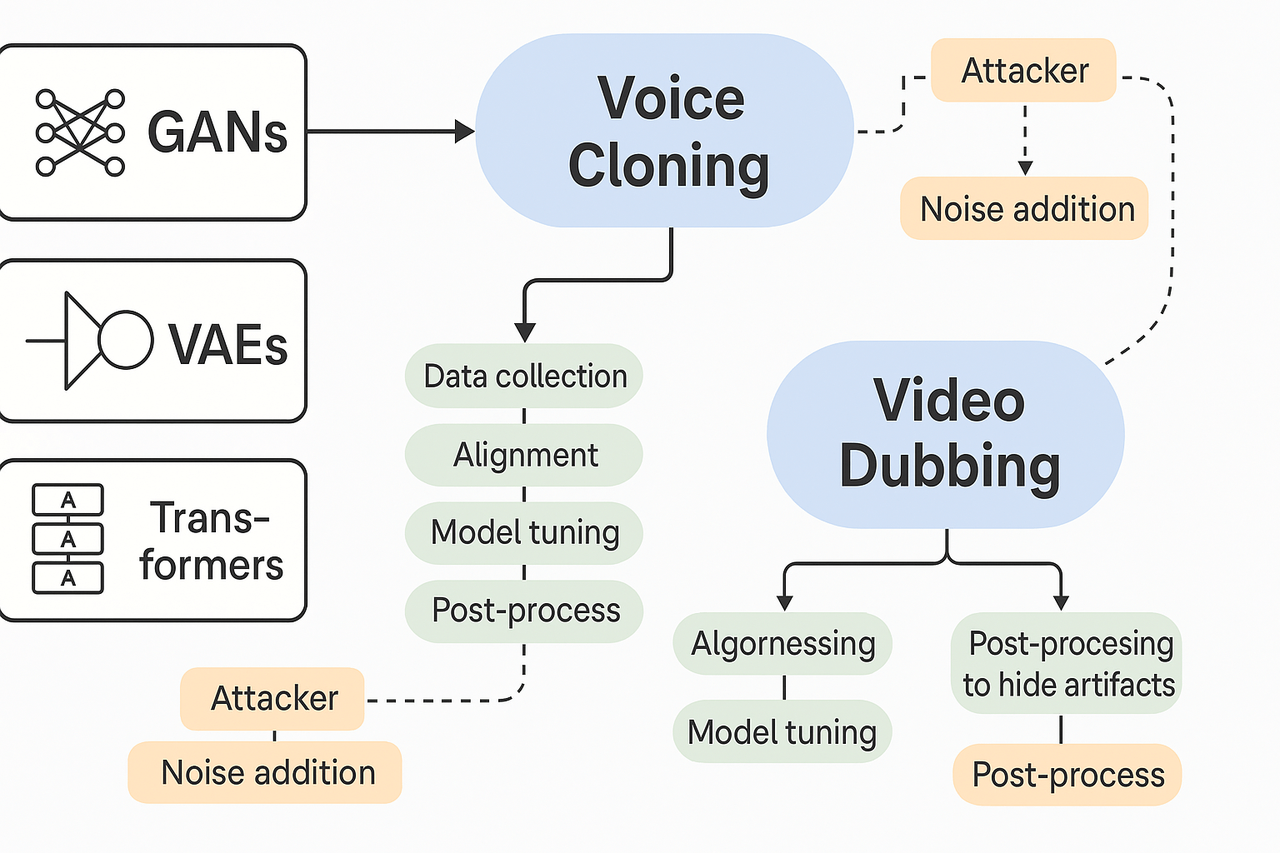
Modern generative models make audio and dubbed video that look and sound real. This short primer explains how methods like GANs, VAEs, and Transformer models create content. It also lays out the common attacker steps, so readers can see why some detector signals work and why others fail.
Core generative methods and what they do
Generative Adversarial Networks, or GANs, pit two networks against each other. One network generates content, the other judges realism. This pushes the generator to make sharper images and video frames.
Variational Autoencoders, or VAEs, compress data into a simple code, then decode it back. They make smooth, controllable outputs but can blur fine detail. That blurring can leave subtle fingerprints in audio or video.
Transformer-based models learn long-range patterns in audio and text. They predict the next sound or token, so they excel at voice cloning and coherent lip-synced captions. Transformers scale well and power many recent dubbing tools.
Typical voice-cloning and dubbing pipeline
-
Collect target audio and transcripts, often a few seconds to minutes.
-
Clean and align audio to text, split by speaker segments.
-
Train or fine-tune a model to mimic timbre and prosody.
-
Generate new speech in another language, then retime for lip sync.
-
Merge audio with video, adjust subtitles, and render.
Attackers follow the same steps but omit consent and safety checks. They may also post-process audio to hide artifacts, like adding noise or EQ.
Why detectors catch or miss fakes
Detectors look for spectral anomalies, timing errors, and bad lip-sync. They also use multi-modal checks that compare audio, video, and text. But models can fix those flaws, and datasets can bias detectors. Watermarks and provenance tools help, yet adoption is uneven.
Understanding the creation chain clarifies which signals are robust. It also shows where to place checks in your workflow, from input collection to final render.
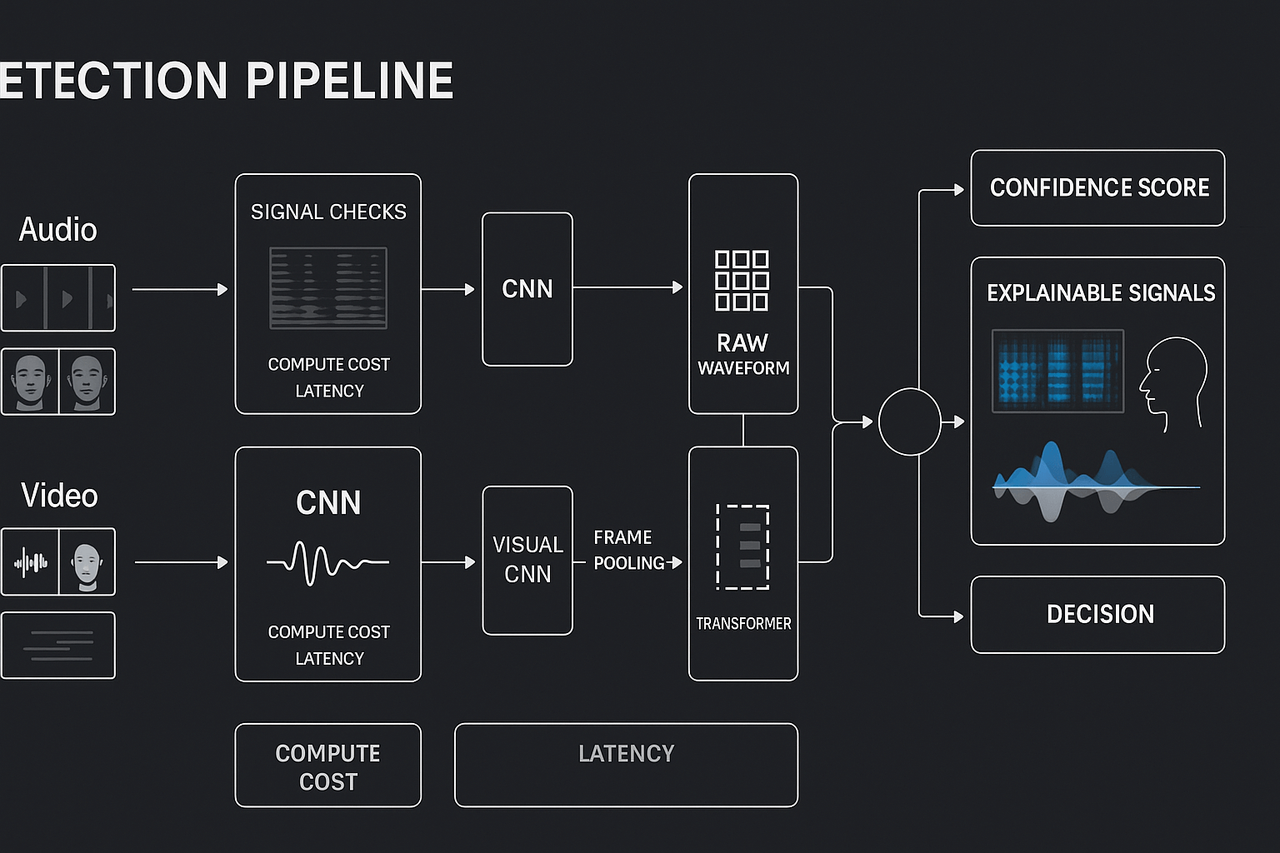
Deepfake detection techniques: audio, video and multi-modal approaches
This section surveys practical methods for identifying synthetic media, emphasizing measurable trade-offs in accuracy, latency, and robustness. It highlights signal-level forensics, machine learning classifiers such as CNNs and Transformers, and fusion strategies that combine audio and video signals for higher confidence detections.
Signal-level forensics: quick and explainable
Low-cost signal checks act as the first line of defense. Audio analyses include spectrogram irregularities, unnatural frequency patterns, and residual vocoder noise. Video checks assess blinking patterns, frame consistency, and head pose alignment.
Key techniques:
-
Audio: Examine MFCCs, phase continuity, and voice artifacts.
-
Video: Detect frame-level inconsistencies, unnatural movements, and facial landmarks.
-
Lip-sync: Match phoneme timing with mouth movements.
While efficient, these approaches may fail under compression or advanced generative models.
Machine Learning classifiers: deep detection
Advanced models go beyond human detection capability. CNNs work well on structured data like spectrograms and image frames. Transformers model long-range dependencies, capturing temporal mismatches.
Types of models:
-
CNNs for audio/video frame artifact classification.
-
Raw waveform models for subtle audio manipulations.
-
Transformers for temporal consistency across segments.
Trade-offs:
Multi-modal fusion: robust decision making
Combining modalities enhances detection fidelity:
-
Early fusion: Merges features from both streams before modeling.
-
Mid-level fusion: Joins intermediate representations from separate audio/video models.
-
Late fusion: Uses ensemble logic on independent detector outputs.
Recommendation: Use lightweight checks initially, and escalate suspected cases to a fused model for in-depth analysis.
Deployment considerations
Common pitfalls and solutions:
-
Domain shift — Use ongoing retraining pipelines.
-
Compression degradation — Employ robust preprocessing.
-
Adversarial edits — Implement augmented training.
-
Overfitting to known fakes — Curate diverse datasets.
-
Opaque outputs — Build explainable tools like heatmaps and lip-sync timelines.
Checklist for engineers
-
Monitor per-stage latency.
-
Enable explainable results for audit.
-
Store raw detections and logs.
-
Calibrate based on content type.
-
Maintain a diverse, updated benchmarking suite.
A layered approach — combining signal checks, deep models, and fusion logic — gives you reliable, scalable deepfake detection.
Benchmarks & practical tools: from research to production
Start with real datasets and clear metrics. This section maps the major public corpora, explains common scores, and flags benchmarking traps you must avoid. It helps teams design repeatable tests that reflect real workflows for audio and video deepfake detection techniques.
Key open datasets
Researchers and engineers rely on a few standard corpora to train and test detectors. For face-video work, FaceForensics++ (FF++) supplies manipulated video clips with edits and compression variants. For speaker and audio spoofing tasks, the ASVspoof family is widely used. For speaker identity and transfer tests, VoxCeleb offers large-scale natural speech from many speakers. For voice spoofing work, the ASVspoof 2019 dataset includes
ASVspoof 2019 dataset description 54,000 bona fide samples and 233,960 spoofed samples, making it a heavy benchmark for audio detectors.
|
Dataset
|
Modality
|
Typical size
|
Common use
|
|
FaceForensics++ (FF++)
|
Video
|
1k+ clips
|
Face manipulation detection and compression studies
|
|
ASVspoof (2019 variant)
|
Audio
|
200k+ samples
|
Spoof detection, TTS and VC attacks
|
|
VoxCeleb
|
Audio/video
|
100k+ utterances
|
Speaker ID, voice transfer, speaker verification
|
Metrics and common benchmarking pitfalls
Pick metrics that match your risk model. Report equal error rate (EER), area under the curve (AUC), false positive rate (FPR) at fixed true positive rate (TPR), and per-class precision. Explain EER and AUC on first use: EER is the error rate where false positives equal false negatives, and AUC measures ranking quality.
Beware common traps. High accuracy on FF++ does not mean the model handles real compression, lighting, or unseen generators. Cross-dataset testing catches overfitting. Also watch for training-test contamination, leaked speaker identities, and unrealistic balancing that hides rare but costly false positives.
Open-source tools and commercial detectors
Start with community tools for prototyping: PyTorch/CV and TensorFlow model forks for FaceForensics++, and Kaldi or torchaudio stacks for ASVspoof. For multi-modal fusion, try open frameworks that accept synchronized audio and video inputs.
For production, evaluate vendors on latency, throughput, explainability, privacy, update cadence, and false alarm cost. Ask for calibration data, fail-open policies, and API SLA terms. Prefer models that output confidence scores, per-frame heatmaps, and audio features so non-technical teams can audit decisions.
A reproducible test checklist
-
Define threat scenarios and datasets that reflect them.
-
Create speaker and content holdouts, plus cross-dataset splits.
-
Measure EER, AUC, and FPR@TPR, with confidence intervals.
-
Simulate distribution shifts: codecs, noise, re-recording.
-
Log raw predictions and seed experiments for repeatability.
This checklist lets teams compare detectors fairly and pick tools that work under real operational constraints.
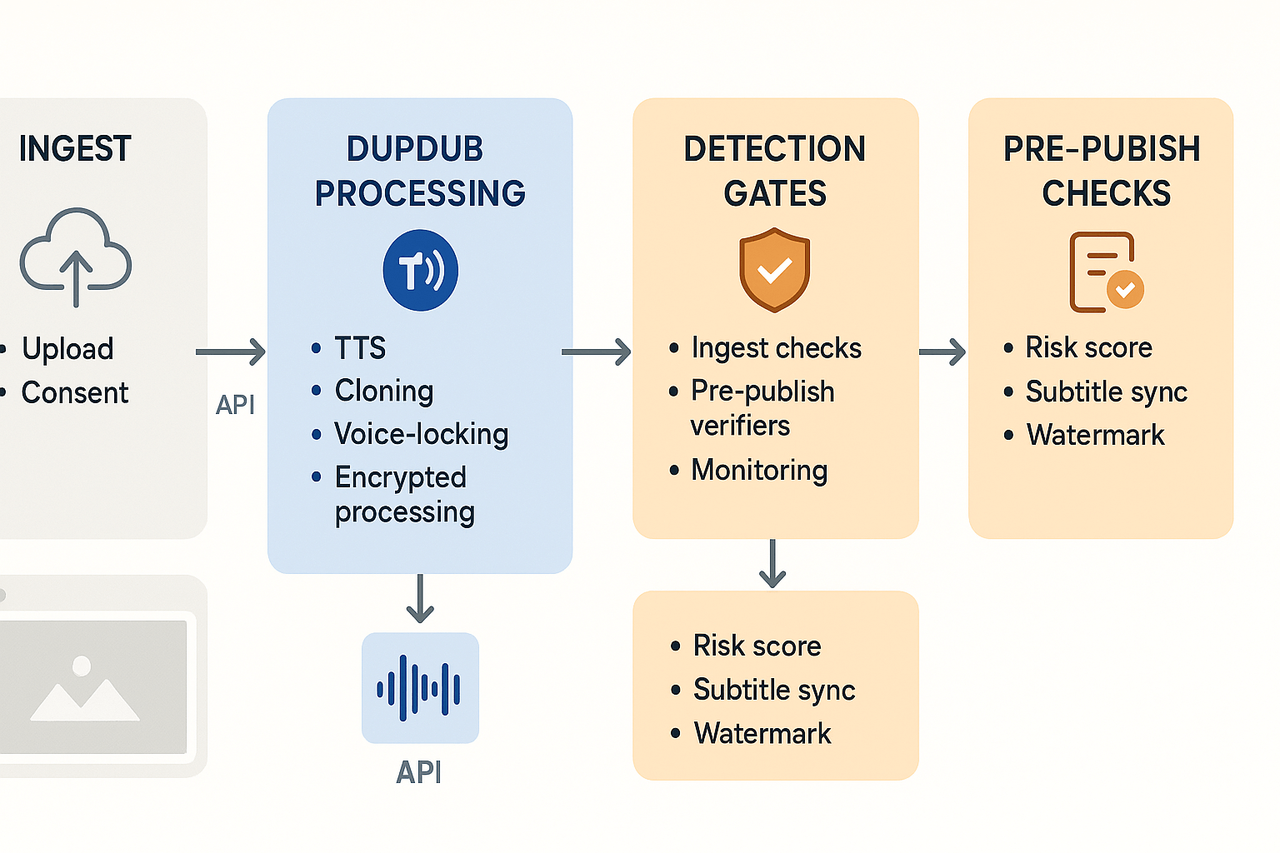
Implementing detection in content workflows, a DupDub-focused playbook
Start here: integrate detectors where they stop risk, not where they slow teams. This playbook maps three practical detection gates: ingest, pre-publish, and post-publish monitoring. It shows how DupDub features like voice-clone locking, encrypted processing, and API automation slot into each gate. You’ll get example API snippets and a reproducible workflow you can drop into localization or e-learning pipelines.
1) Gate placement, fast and simple
Place detections at three moments: Ingest, to flag unverified source audio or suspicious uploads. Pre-publish, to validate cloned voices, translations, and subtitle sync. Monitoring, to catch reuploads, takedown risk, or brand-safety drift. This three-gate model reduces false positives and keeps publishing fast.
2) What each gate should do
Ingest checks the source for provenance, speaker consent, and basic artifacts. Use short, automated tests like audio fingerprinting and ASR (speech-to-text) consistency checks. Pre-publish runs stronger models, multimodal checks, and watermark verifiers on cloned voices. Monitoring runs lighter models in the background and uses heuristics to trigger human review.
3) How DupDub maps to gates
DupDub features plug in naturally to each gate:
-
Ingest: Use DupDub’s encrypted processing to keep raw uploads private. Lock voice clones to the original speaker to prevent unauthorized reuse.
-
Pre-publish: Validate cloning outputs against locked voice metadata. Confirm subtitle alignment and transcription via DupDub’s STT and SRT tools.
-
Monitoring: Call DupDub’s API to re-run fingerprints and compare public assets to your locked voice models.
These mappings help preserve brand voice while keeping security and compliance in place.
4) Scalable automation, sample API snippets
Here are minimal examples to get CI/CD teams started. First, upload and request a clone lock:
POST /v1/uploads – Upload audio with API key and file
POST /v1/voice-clones/lock – Lock a clone to the original speaker with a consent requirement
Next, run a pre-publish verification call that returns a risk score:
POST /v1/verifications/prepublish – Input asset ID and enable checks (watermark, speaker-match, subtitle-sync)
Use the returned score to gate publishing in your pipeline.
5) Operational checklist and assets
Use this quick checklist for rollout:
-
Require consent and clone locking at ingest.
-
Add a pre-publish verification step with a risk threshold.
-
Schedule automated monitoring scans daily.
-
Route medium-high risk to human reviewers.
We recommend storing a downloadable workflow diagram and screenshots in your internal SOPs. The diagram should label modules TTS, Cloning, SRT, and API, and show where detectors run.
Policy, legal, and ethical trends: what content teams must track
Deepfake detection techniques are now a legal and compliance priority. Content teams must track labeling, provenance, and watermarking rules as they plan voice cloning demos and public trials. This short guide flags regional moves and practical steps to keep demos safe and compliant.
Global trends to watch
Regulators want clear signs when content is synthetic. The European Union is leading with rules that require marking AI output. The EU's rule is explicit: according to
Regulation (EU) 2024/1689, AI-generated content must be marked using techniques such as watermarks, metadata identifications, or cryptographic methods to prove provenance and authenticity. In the United States, agencies issue guidance and expect platforms to add transparency labels, while standards groups push for interoperable metadata formats.
Practical actions for content teams
-
Map risk by region: list where content will publish and the local rules that apply.
-
Enable provenance metadata: include origin, model, and consent fields in files and APIs.
-
Apply robust watermarking: use detectable, persistent markers for audio and video.
-
Log consent and cloning records: keep timestamps, speaker consent, and sample sources.
-
Add user-facing labels: surface "synthetic" badges and transcript notes in players.
-
Combine detection and human review: auto-flag deepfakes, then route high-risk items for manual review.
-
Limit public demos: use private trials or watermark demos to avoid misuse.
-
Retain audit trails: keep records for the statutory window in each jurisdiction.
Start with a short compliance checklist, and embed metadata and demo guardrails into your workflow. Monitor rule updates and coordinate with legal before public launches. This keeps teams ready, and makes voice cloning safer for users and brands.
Good detectors explain themselves in plain language so creators and reviewers can act quickly. Start reports with a one‑line verdict and a short rationale. Mention the suspected artefact (audio, video, or both) and the key signal that triggered the alert. This reduces confusion and cuts time spent chasing benign edits.
Show clear, explainable signals
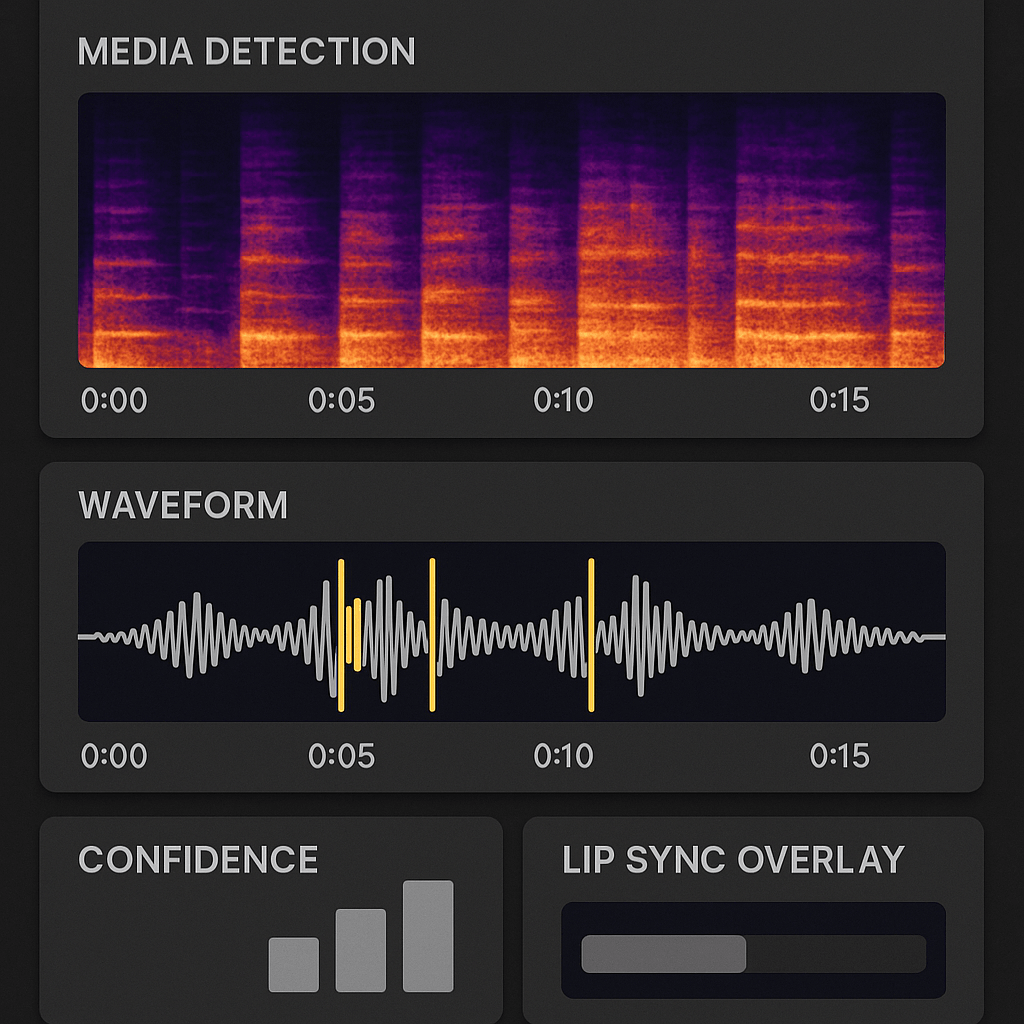
Surface simple, visual evidence alongside any score. Include a spectrogram (frequency versus time) view for audio anomalies, a waveform with highlighted segments, and a side‑by‑side mouth tracking overlay for lip sync issues. Label each signal in plain text, for example: "High spectral noise in 2–4 kHz, likely synthetic". Explain jargon on first use, for instance, a spectrogram is a visual map of sound energy across frequencies.
Design UI patterns that build trust
Use consistent, predictable UI elements so reviewers know what to expect. Recommended patterns:
-
Confidence band: color-coded low/medium/high with thresholds and a short sentence about what each band means.
-
Evidence panel: expandable tiles for spectrograms, lip sync plots, and frame-level artifacts.
-
Play-through controls: scrub timeline with flagged moments and A/B playback between original and suspect audio/video.
-
Provenance tags: show source file name, upload time, and any processing steps.
These features let users move from doubt to decision fast.
Train teams, reduce noise, and educate your audience
Run short, hands‑on sessions with real, consented examples. Teach reviewers how to check three things: score, visual evidence, and context. Create a small decision playbook: when to accept, when to ask for consent, and when to escalate. Publish simple help pages and quick demos so creators can self‑serve. That lowers false positives and improves acceptance of detection tools.
By pairing clear signals with smart UI and lightweight training, detectors become usable tools for localization and content teams. No jargon, just actionable evidence.
Business recommendations & roadmap: layered defenses and readiness checklist
Start with a clear, phased plan that balances fast wins and durable controls. Implementing deepfake detection techniques should protect users today while enabling better models and workflows tomorrow. This roadmap helps product and engineering leads prioritize watermarking, two-factor voice controls, benchmarking, and detection pipelines while setting trial KPIs for DupDub evaluation.
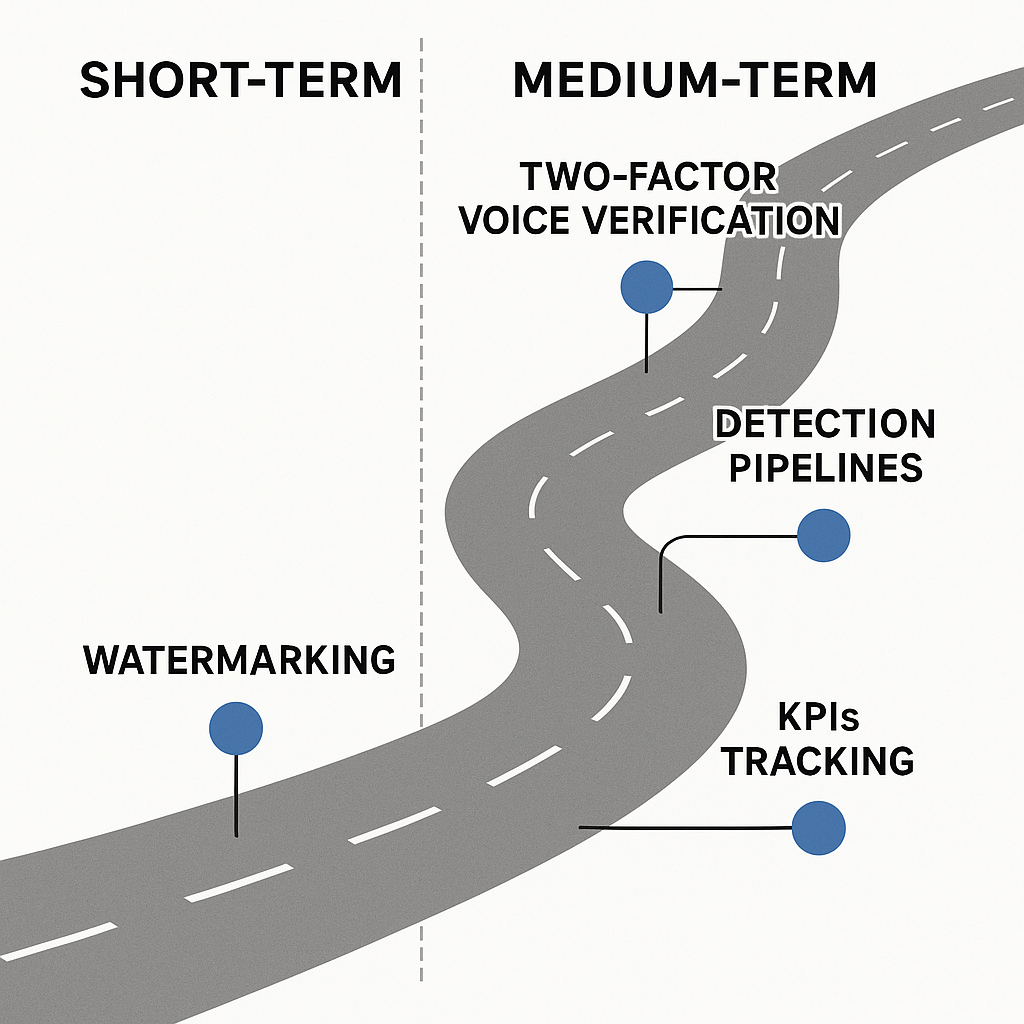
Short-term wins (0–6 months)
Focus on inexpensive, high-impact controls you can ship quickly.
-
Deploy active watermarking in generated audio and video (a hidden signal that proves origin).
-
Add two-factor voice verification (2FA for voice) for cloning requests: require consent plus a time-limited token. Explain 2FA to users during enrollment.
-
Instrument simple detection gates: integrate off-the-shelf classifiers to flag high-risk uploads before publication.
-
Start lightweight benchmarking with a small test set that mirrors your content types.
Medium-term investments (6–18 months)
Build scalable, production-grade defenses.
-
Pipeline automation: queue-based analysis, score aggregation, and human review routing.
-
Multi-modal detectors: combine audio, visual, and metadata signals for higher accuracy.
-
Forensic logging and secure storage of flagged artifacts for audits.
-
Regular model retraining and adversarial testing using synthetic samples.
KPIs and readiness checklist
Track metrics that show impact and operational health.
-
False positive and false negative rates by content type.
-
Time to detect and time to remediate.
-
Percentage of content with embedded watermarks.
-
Trial KPIs: detection precision, user friction score, and cost per flagged item.
Incident response essentials
Keep a short playbook: triage, notify stakeholders, revoke cloned voices, and publish a transparency note when appropriate. Test this plan in tabletop exercises every quarter.
FAQ — Answers to common questions about deepfake detection
-
Can DupDub detect deepfakes using deepfake detection techniques?
Short answer: DupDub does not advertise a built-in forensic detector, but its platform includes tools that help teams spot artifacts and verify consent. You can compare source audio, transcripts, and voice clones inside the studio to find mismatches. For full forensic checks, pair DupDub workflows with a dedicated detector and a human review step.
-
What deepfake detection accuracy should teams expect in production?
Expect a range: research models can be strong on lab data, but real-world accuracy falls with noisy audio, translation, or heavy postprocessing. Treat detectors as risk flags, not final verdicts. Use human review for high-stakes content.
-
What steps should you take when a deepfake is discovered in the workflow?
1. Quarantine the file and record metadata. 2. Run a second independent detector and human review. 3. Notify stakeholders and preserve evidence. 4. Remove or label the content and update controls.
-
How do I add detection into a DupDub content workflow for localization teams?
Use automated transcripts, side-by-side audio comparison, and gated approvals in the studio. Integrate an external detector at the upload or pre-publish step.
-
Are the detection results explainable to non-technical reviewers?
Yes, aim for simple outputs: confidence scores, highlighted suspicious segments, and short human-readable notes. That makes compliance decisions faster.


 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook