

TL;DR — What you'll learn about emotion TTS and DupDub
-
Test two voice modes: neutral and emotional, on the same script.
-
Run a short A/B test on retention or comprehension.
-
Confirm consent, privacy, and export limits before cloning voices.

Core terms made simple
-
Nuance (small expressive changes): tiny timing or emphasis shifts that change meaning. Nuance helps a line feel sincere or playful.
-
Prosody (rhythm and intonation): the pattern of rises and falls in speech. Good prosody makes sentences flow and shows whether a line is a question or a fact.
-
Pitch (highness or lowness of voice): changes in pitch signal emotion and focus. A higher pitch can feel excited, a lower pitch can feel calm.
-
Timbre (voice color): the unique texture of a voice, like breathiness or warmth. Timbre makes one synthetic voice sound distinct from another.
Why emotional speech matters today
-
Engagement: Listeners stay longer and respond better to expressive narration.
-
Accessibility: Emotional cues reduce misunderstandings for diverse learners.
-
Localization: Emotion-aware voices preserve intent across languages.
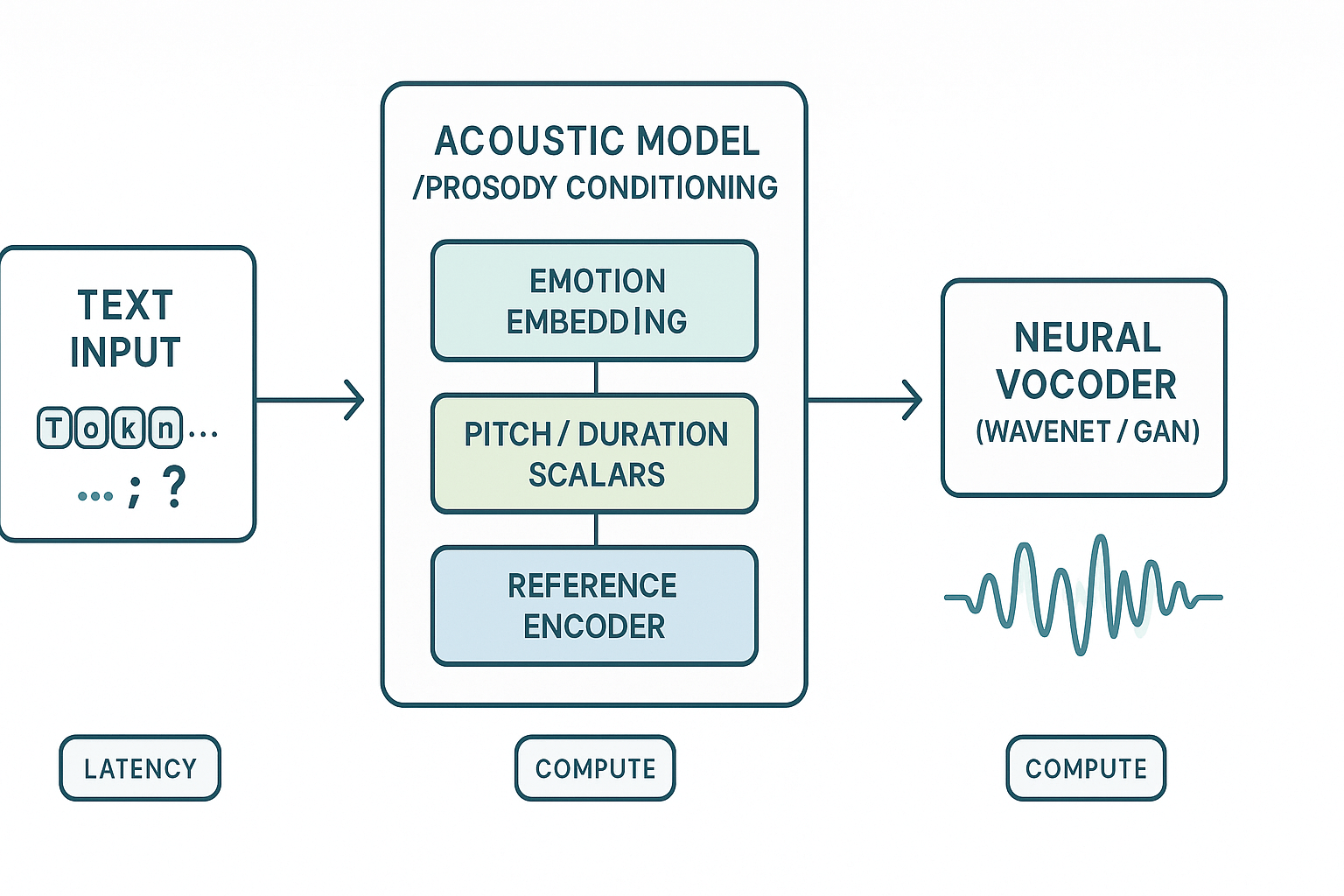
How emotion-enabled neural TTS works (technical overview)
Core building blocks
How emotion conditioning works
-
Learned embeddings that represent discrete emotions (happy, neutral, angry).
-
Continuous prosody controls for pitch, duration, and intensity.
-
Style tokens or reference encoders that copy prosodic features from a sample.
Voice cloning and cross-lingual mapping
Trade-offs creators should know
-
Latency: smaller acoustic models and neural vocoders reduce delay but can lose subtle expression.
-
Compute: high-fidelity vocoders need GPUs for real-time synthesis.
-
Perceived quality: more parameters usually produce more natural emotion, but require careful tuning.
DupDub deep dive: emotion, nuance and pitch controls
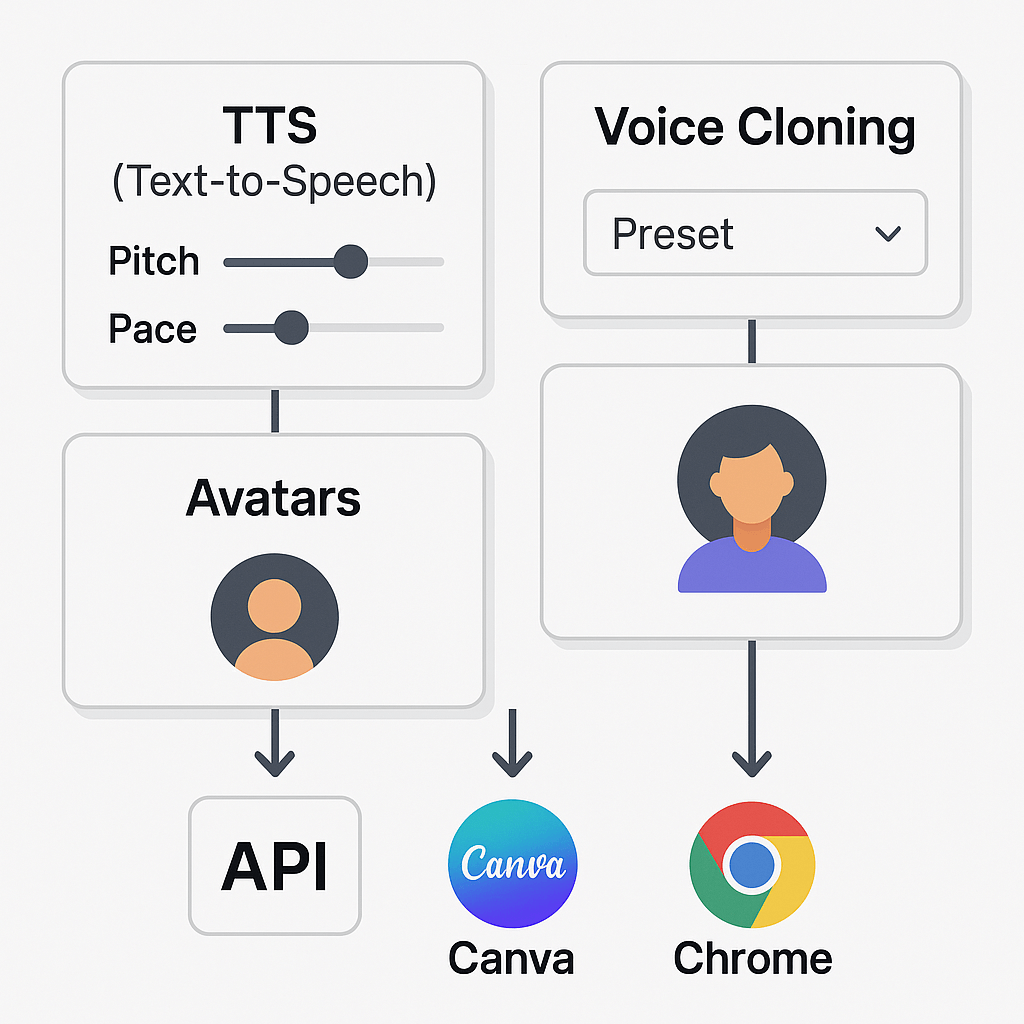
Map controls to DupDub modules
-
Presets and styles: choose a base mood, like neutral, warm, or excited. Presets alter timbre and phrasing.
-
Pitch and pace sliders: fine tune pitch (higher or lower) and speed independently. Small changes make speech feel more natural.
-
Voice cloning options: clone a speaker, then layer emotion styles or manual sliders for nuance.
-
Avatars and dubbing studio: apply the same voice with synced subtitles and video alignment for localization.
Cloning samples, languages, exports, and security
|
Feature
|
Details
|
|
Cloning sample
|
30 second sample creates a synthetic voice (multilingual)
|
|
Supported languages & accents
|
47 languages, 50+ accents (see product docs)
|
|
Export formats
|
MP3, WAV, MP4, SRT
|
|
Integrations
|
API, Canva, Chrome extension, YouTube transcript plugin
|
|
Security & compliance
|
Cloning locked to original speaker, encrypted processing, GDPR-aligned
|
|
Voice clones per plan
|
Free trial: 3; Personal: 3; Professional: 5; Ultimate: 10
|
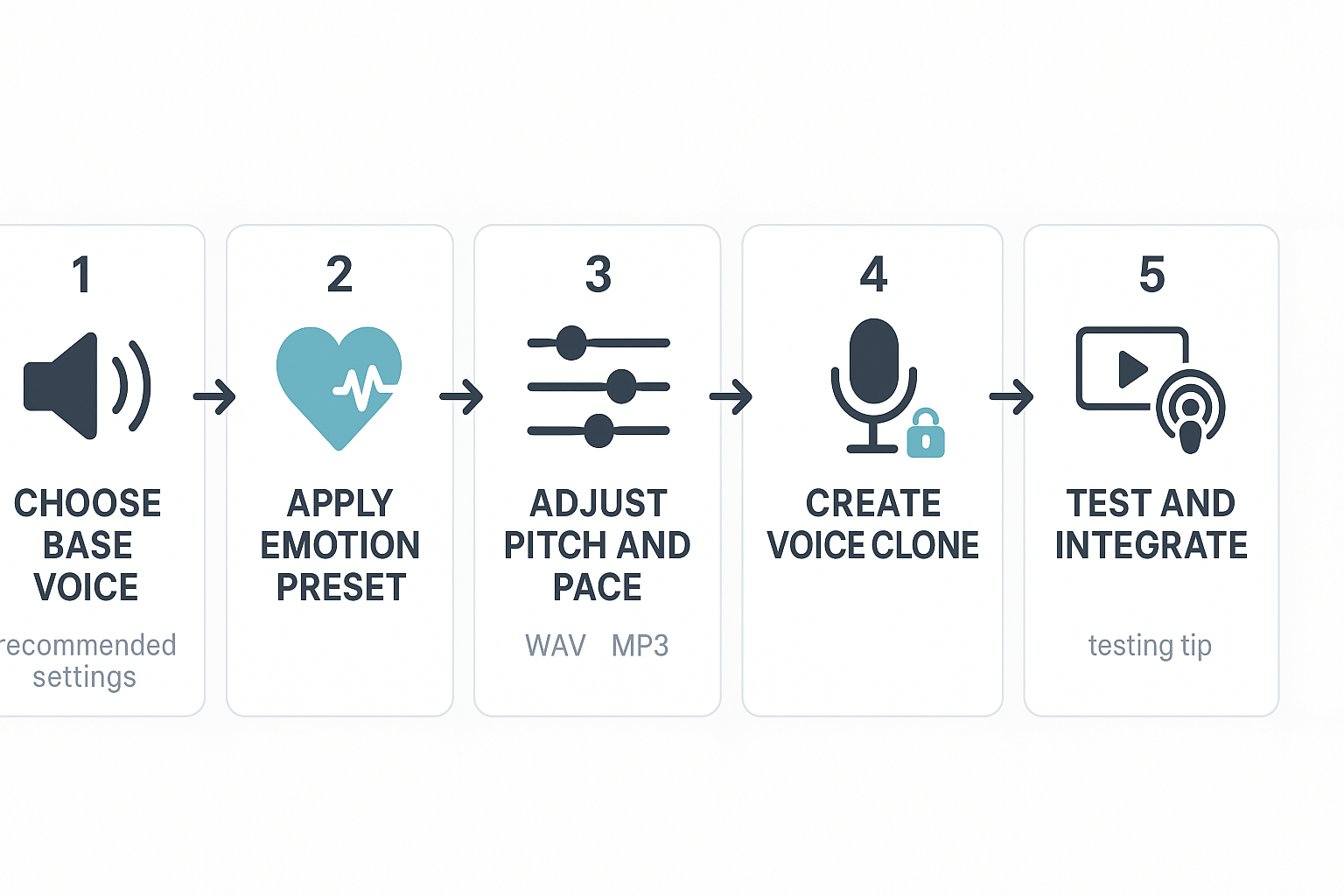
Step-by-step: Designing an emotional voice in DupDub
1) Choose a base voice and emotion preset
2) Adjust pitch, pace, and intonation
3) Create a voice clone when you need consistency
4) Quick A/B testing methods
5) Integrate the final audio into workflows
Best tips and troubleshooting
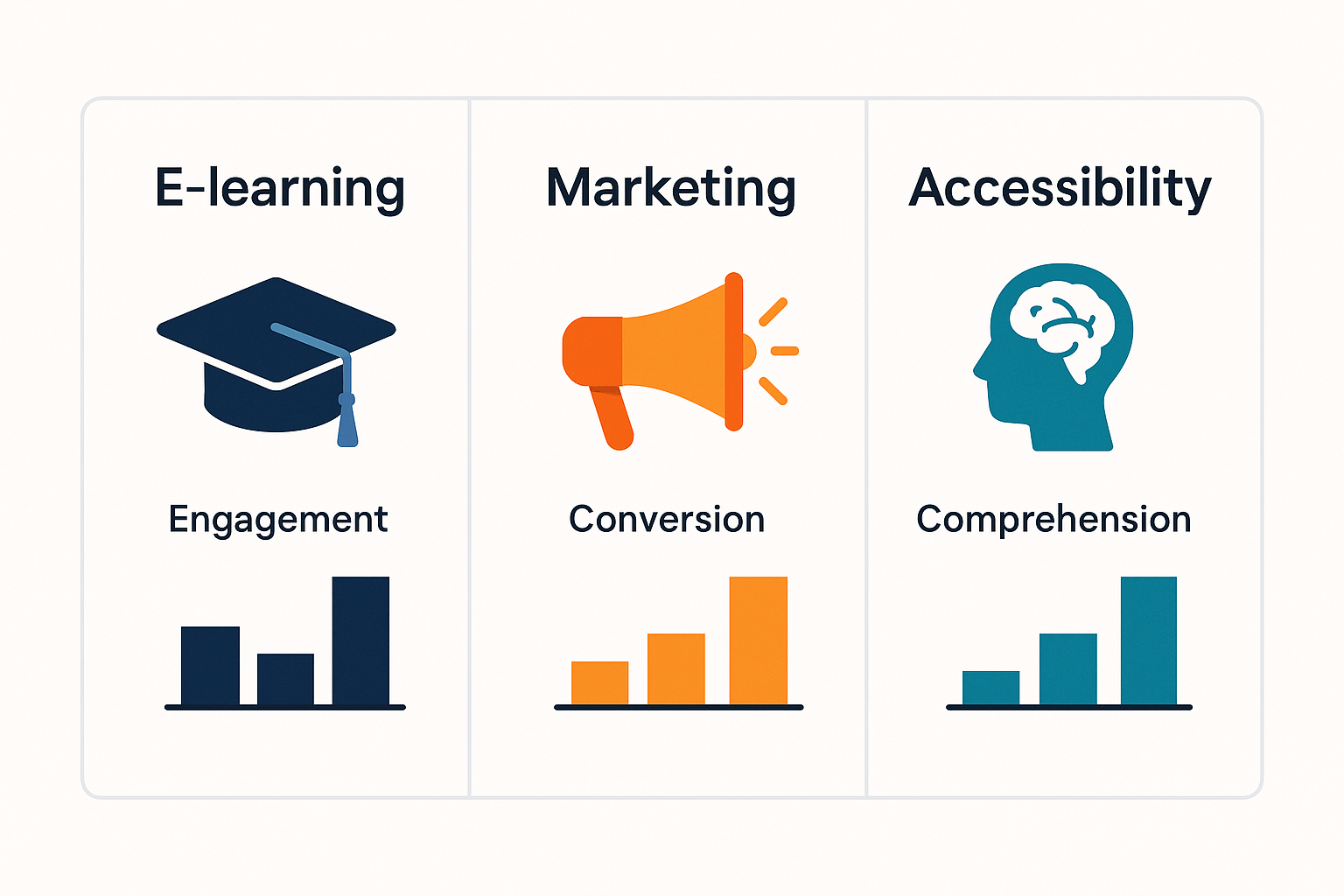
Use cases and mini case studies (real-world impact)
E-learning: higher course completion and recall
Marketing: better ad performance and CTR
Accessibility: clearer audio for neurodiverse listeners
-
E-learning: +18 percent completion, faster content fixes.
-
Marketing: +12 percent CTR, lower acquisition cost.
-
Accessibility: +20 percent comprehension, fewer re-records.
Feature comparison table
|
Feature
|
DupDub
|
ElevenLabs
|
Murf AI
|
Play.ht
|
Speechify
|
Synthesys
|
|
Emotion controls (granularity)
|
Fine-grained emotion, nuance, pitch sliders
|
Strong expressive styles, prosody controls
|
Mood presets, limited fine control
|
Style tokens and SSML support
|
Basic expressive voices
|
Preset emotional styles
|
|
Voice cloning limits
|
3-10 clones by plan; 30s sample
|
Multiple clones, commercial options
|
1-5 clones per plan
|
Clone options via pro plans
|
Focus on narration, fewer clones
|
Voice cloning on premium tiers
|
|
Language coverage
|
90+ TTS, 47 clone languages
|
Wide language set, mainly TTS
|
50+ languages
|
70+ languages
|
30+ languages
|
40+ languages
|
|
Export formats
|
MP3, WAV, MP4, SRT
|
MP3, WAV
|
MP3, WAV, SRT
|
MP3, WAV
|
MP3
|
MP3, WAV
|
|
Integrations & API
|
Canva, Chrome plugin, API, YouTube tools
|
API, SDKs, plugin ecosystem
|
API, LMS connectors
|
API, WordPress, Zapier
|
Chrome reader, apps
|
API, studio integrations
|
Pricing snapshot and best-fit buyers
-
DupDub: Free 3-day trial; Personal $$11/yr, Professional$$30/yr, Ultimate $110/yr. Best for creators who need dubbing, cloning, and avatars in one place.
-
ElevenLabs: Premium pricing, strong if you need highly natural read voices and SDK access. Good for publishers and audiobooks.
-
Murf AI: Mid-market, strong studio tools for e-learning. Good for instructional designers.
-
Play.ht: Value option for multi-voice TTS at scale. Good for blogs and simple narration.
-
Speechify: Reader-first, helpful for accessibility and personal use.
-
Synthesys: Studio-focused, useful for marketing voiceovers.
Quick summary: strengths and trade-offs
Ethics, privacy & compliance for emotional TTS
Action checklist for teams
-
Get written consent that describes use cases and emotional styling. Keep a signed record.
-
Minimize data: use only the audio needed for a clone.
-
Encrypt files in transit and at rest, and limit access to keys.
-
Set retention limits and audit logs for voice models.
-
Publish a responsible-use policy that bans impersonation and misuse.
Limitations, troubleshooting and best practices for voice design
Quick fixes for common production issues
-
Flat or robotic delivery: add short parentheticals like (softly), (surprised), or increase emotion intensity parameter. Test several variants.
-
Mis-timed breaths or pacing: insert commas and pause tokens, or use explicit SSML pauses for fine control.
-
Odd consonant clipping or sibilance: try a different voice model or lower pitch modulation.
Voice design best practices
-
Start with a reference script, record human demos, and match prosody in prompts. Keep sentences short. Iterate with A/B tests.
-
Use consistent style guides for brand tone and accessibility.
When to combine synthetic and human voice
Final QA checklist
-
Listen for emotion accuracy and timing. 2. Check transcription and subtitles. 3. Validate privacy flags and consent for clones.
FAQ — People also ask + action items
-
Is emotion TTS legal for commercial voice cloning?
Short answer: usually yes, but it depends. Commercial use is legal when you own the voice or have clear consent. Laws vary by country, so check local right-of-publicity rules and platform terms.
-
How realistic are emotional TTS voices in production environments?
Modern neural models can sound very natural for many use cases. Expect high realism for narration, e-learning, and localized video. But edge cases like nuanced acting still need human review.
-
Do I need consent to create a voice clone with emotion TTS?
Yes, always get explicit consent from the speaker. Written permission protects you from legal and ethical risk. For public figures, platform rules may still forbid cloning without permission.
-
Which industries fit emotion-enabled TTS for accessibility and e-learning?
Top fits include e-learning, customer support, marketing, and media localization. Use cases: audio descriptions, interactive lessons, personalized marketing, and dubbed content for global audiences.
-
What quick action items should I follow to try emotion TTS safely?
1. Test with non-identifying samples or your own voice.
2. Read terms and get written consent for clones.
3. Start a small pilot to evaluate quality and workflow.
4. Compare plans and developer options before scaling.
 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook