

TL;DR: What you’ll learn and quick takeaways
-
Exact SSML tags to control prosody, pauses, emphasis, and pronunciation.
-
How to combine prosody, break, and say tags for natural pacing.
-
SSML patterns for emotion and speaking styles, with safe fallbacks.
-
Voice cloning integration tips for consistent multilingual output.
-
A test plan using MOS (mean opinion score), AB tests, and latency checks.
-
Cost-aware engineering notes: batching, caching, and Ultra vs Standard voices.
-
API-first patterns: templated SSML payloads and streaming vs batch calls.
What is expressive TTS and why SSML matters
SSML as the control layer for prosody and voice
-
Increased engagement: natural pacing and emphasis keep listeners focused.
-
Clearer multilingual UX: locale-aware pronunciations and voice switching improve comprehension.
-
Brand consistency: cloned or style-matched voices preserve tone across channels.
-
Fewer support calls: clearer prompts reduce user errors in voice UIs.
Why engineers should treat SSML as a first-class spec
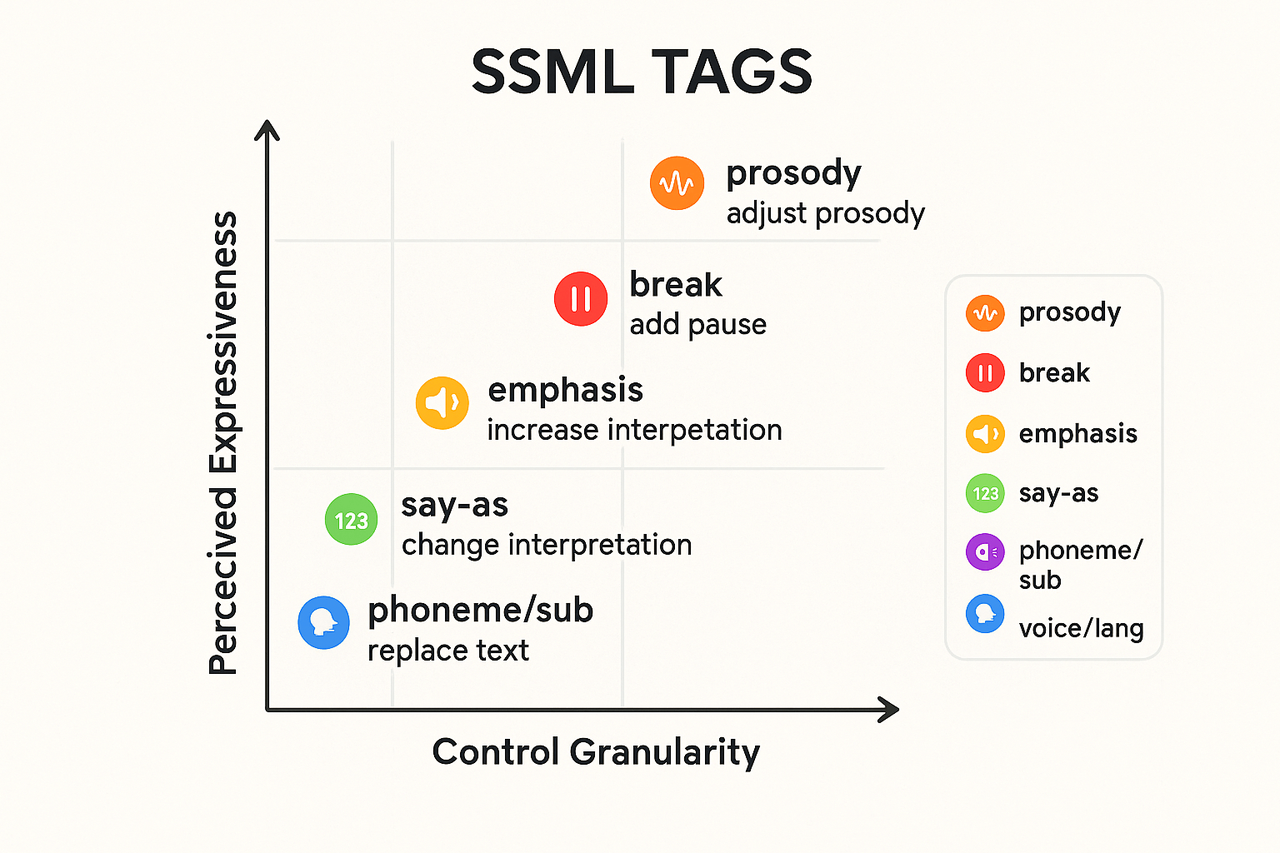
Prosody: control pitch, rate, volume
<prosody rate="85%" pitch="-2st"> slows and deepens a line. Expected outcome: slower, weightier delivery that feels calmer or more serious. Use conservatively, small steps feel natural.break: tune pauses and phrasing
<break time="350ms"/> adds a short pause. Expected outcome: clearer phrasing, better comprehension, or a beat after a punchline. Use variable lengths to mirror natural breathing.emphasis: highlight words
<emphasis level="moderate">important</emphasis>. Expected outcome: those words sound stronger, drawing listener's attention. Use for calls to action, dates, or names without changing pitch manually.say-as: format interpretation
<say-as interpret-as="telephone">8005551212</say-as>. Expected outcome: correct, unambiguous rendering for structured data. This avoids misreads that break trust.phoneme/sub: fix pronunciation
<phoneme> to supply phonetic spelling, or <sub> to substitute spoken text. Example: <phoneme alphabet="ipa" ph="ˈmɑːnə">manna</phoneme>. Expected outcome: consistent, predictable pronunciation for names and jargon. Vital for localization and brand terms.voice + language switching: multilingual flows
<voice name="..."> or <lang xml:lang="es-ES"> to change the speaker or language. Example: <voice name="alloy">Hola</voice>. Expected outcome: seamless multilingual passages, or per-character voices in dialogues. Use with care to avoid jarring timbre shifts.-
Prosody: mood and tempo control.\
-
break: phrase and rhythm.\
-
emphasis: focal stress.\
-
say-as: structured data rendering.\
-
phoneme/sub: atomic pronunciation fixes.\
-
voice/lang: speaker and language switching.
Advanced SSML patterns, testing, and developer tips
Safe tag nesting and fail-safe patterns
-
Only one prosody tag per clause. Keep changes short.
-
Use emphasis for single words or short phrases, not whole sentences.
-
Prefer speaking> paragraph > sentence structure for long content.
Combine prosody and emphasis for nuance
-
Base sentence uses prosody for a consistent brand tone.
-
Apply emphasis to a keyword inside that prosody block.
-
Add a subtle break before or after the emphasis to allow natural phrasing.
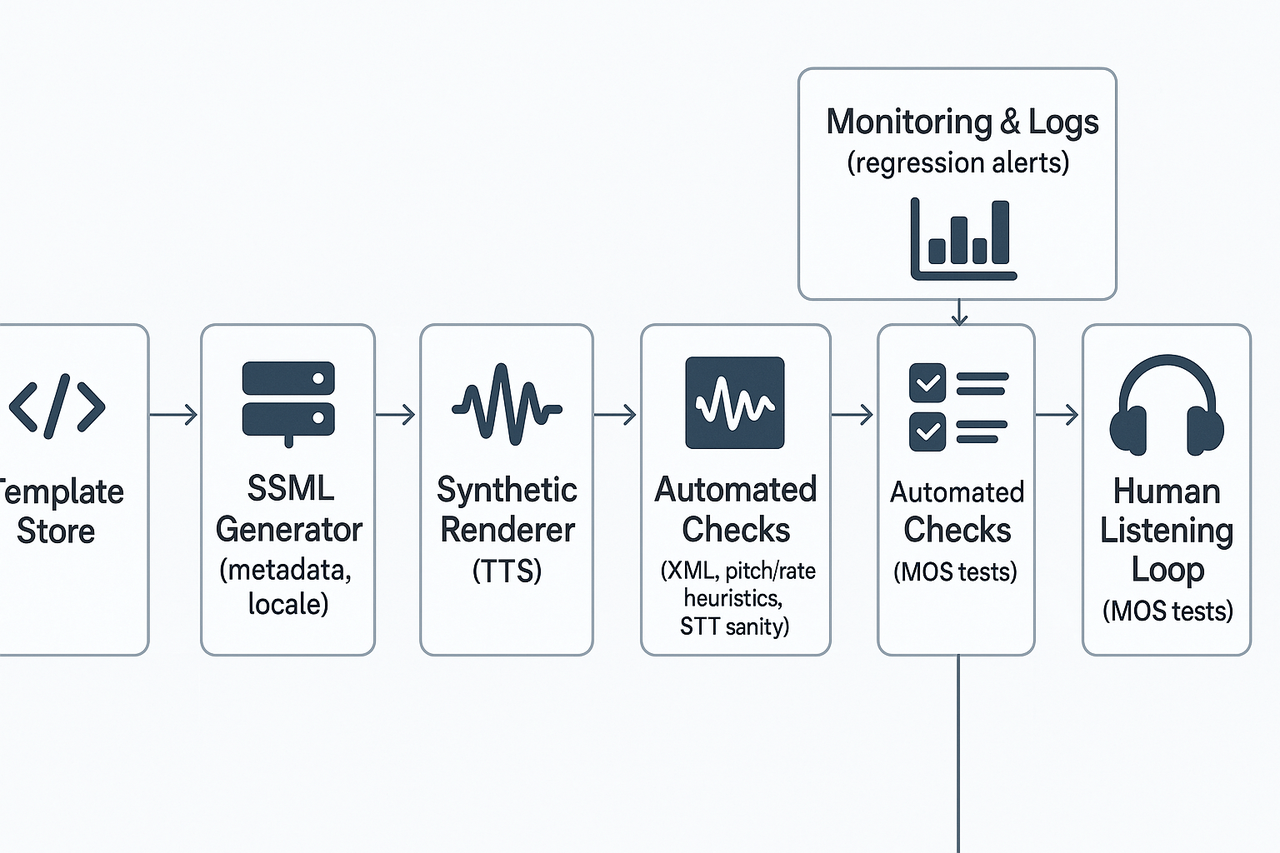
Dynamic SSML generation from templates and metadata
-
Token validation: escape unsupported characters.
-
Tag sanitizer: remove nested prosody or duplicate emphasis.
-
Locale rules: map metadata to voice, break lengths, and numeric formatting.
Testing plans and metrics
-
MOS mean and standard deviation.
-
Intelligibility pass rate for critical phrases.
-
Emotion accuracy, via forced-choice labels.
-
Latency and audio quality failures in CI.
Automated checks and CI integration
-
XML validity for SSML.
-
Tag policy linting to enforce safe nesting.
-
Acoustic heuristics: detect extreme pitch or rate values.
-
Speech-to-text sanity: compare a quick STT transcription to expected text.
Logging, A/B experiments, and regression tracking
-
template_id, metadata, voice_id
-
ssml_hash, render_time_ms, audio_file_id
-
MOS_sample_id, reviewer_id, timestamp
Developer tips and traps to avoid
-
Keep SSML fragments under 300 characters when possible. Short fragments are easier to test.
-
Version templates and tag policies. Treat SSML like code.
-
Use feature flags to roll out new prosody settings gradually.
-
Don’t rely only on synthetic heuristics. Humans catch subtle errors.
How DupDub compares to leading expressive TTS providers
Practical feature comparison
|
Capability
|
DupDub
|
Typical competitors
|
|
Expressive controls (pitch, rate, prosody, styles)
|
Fine-grained SSML-like controls plus preset speaking styles and quick presets
|
Strong prosody controls, sometimes fewer preset styles
|
|
Voice cloning breadth
|
Fast 30s clone, multilingual support (47 languages)
|
High-fidelity clones are often limited to languages or longer training needs
|
|
Languages & styles
|
90+ TTS languages, 1,000+ styles
|
Wide language support, style coverage varies by vendor
|
|
Dubbing & workflow
|
End-to-end AI dubbing, subtitle alignment, avatars
|
Best-of-breed TTS only, often missing video sync tools
|
|
API ergonomics & automation
|
REST API, batching, and media workflows designed for localization
|
Robust APIs but may need more custom glue for video workflows
|
When DupDub is the pragmatic choice
-
You need one platform for dubbing, voice cloning, and multilingual TTS. It cuts integration overhead.
-
You want predictable credits and pricing for rapid POCs.
-
You need subtitle alignment and avatar export in the same flow as TTS.
Trade-offs to weigh
-
Latency: real-time or low-latency streams can be better with specialized streaming TTS services.
-
Cloning fidelity: Boutique cloning providers may yield higher fidelity for ultra-critical voice matches.
-
Enterprise controls: Some vendors provide deeper on-prem or private-cloud options for strict security needs.
-
SSML coverage: check exact SSML tag support if you rely on advanced tag patterns.
Accessibility, ethics, and responsible AI for expressive voices
Consent and secure cloning: practical engineer checklist
-
Get explicit, recorded consent before creating a voice clone. Explain reuse, retention, and revocation rights.
-
Store voice data encrypted at rest and in transit. Use per-customer key management where possible.
-
Lock cloned voices to the original speaker profile and require proof of identity for commercial use.
-
Keep short audit logs of who created or used clones, with tamper-evident controls.
-
Provide an easy revoke flow and a delete pipeline that removes voice models on request.
Governance: bias mitigation and testing checklist
-
Use diverse, representative datasets for training and synthetic testing. Include accents, ages, and speaking styles.
-
Run perceptual tests that check intelligibility, emotion perception, and clarity across groups. Capture both quantitative scores and human feedback.
-
Track metrics for fairness, like equal error rates or intelligibility by subgroup. Re-tune models if gaps appear.
-
Document dataset sources, consent states, and known limitations in a public model card.
Privacy and regional compliance steps
-
Minimize stored personal data and follow data retention rules. Conduct a data protection impact assessment for cloning features.
-
Design for regional law: support data residency, opt-in consent, and age checks per jurisdiction.
-
Pair accessibility testing with WAI best practices and user testing for screen reader and assistive tech workflows.
Real-world use cases & mini case studies (healthcare, education, localization)
Healthcare: clear patient instructions and multilingual outreach
-
Build short, stepwise scripts with explicit action verbs.
-
Add and around critical steps.
-
Run A/B tests with native speakers for wording and SSML.
-
Use DupDub cloning to keep the voice consistent across languages.
Education: adaptive narration that boosts engagement
-
Tag key learning moments with and.
-
Create slow and fast narration presets using values.
-
Integrate the DupDub API to swap voices per learner profile.
-
Run short pilot lessons and capture engagement metrics.
Localization and scalable dubbing: fast, consistent releases
-
Export source subtitles and segment boundaries.
-
Map emotion notes to SSML prosody and emphasis tags.
-
Use DupDub API to batch-generate localized tracks.
-
Run linguistic QA with native reviewers and iterate on SSML.

FAQ — common developer and product questions
-
Can SSML add real emotion to expressive TTS?
SSML itself controls timing, pitch, emphasis, and pauses, so it can make speech sound more expressive and human. You won’t get a novel emotion out of thin air, but careful use of prosody, emphasis, and expressive extensions can convincingly convey mood. Test short before-and-after snippets to validate the effect.
-
How to test SSML tags at scale without manual listening (SSML tags testing at scale)
Automate objective checks first, then sample human tests. Useful steps: - Run a CI job that synthesizes audio from SSML variations. - Use automated metrics: speech rate, pause distribution, pitch range, and transcription quality. - Do stratified human checks on a sampled subset, A/B style. This finds regressions fast and keeps manual listening effort small.
-
Is voice cloning secure on platforms like DupDub (voice cloning security DupDub)?
Good platforms require speaker consent and technical safeguards. DupDub locks clones to the original speaker and uses encrypted processing. For production, enable account controls, review retention settings, and use enterprise contracts for stricter data handling.
-
Accessibility best practices for expressive voices and SSML tags
Prioritize clarity: prefer moderate rates and clear pauses. Add captions and plain-text transcripts. Offer simpler voice variants and test with screen readers. When adding expressiveness, run intelligibility tests with real users, especially people who use assistive tech. Next steps: start the DupDub trial, explore the API docs, or request an enterprise contact to discuss security and compliance.
 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook