Phoneme TTS lets teams send phoneme strings or IPA to a neural voice engine so pronunciation is exact. Use it when proper names, technical terms, or multilingual content must sound correct every time.
-
When mispronunciation harms trust or clarity.
-
For product names, place names, medical or legal terms.
-
When local accents or dialects need precise handling.
-
For short, high-value assets like ads or museum audio.
Practical next steps for product teams: pick a short test set of tricky phrases, build a small phoneme dictionary, and run side-by-side listening tests with native reviewers. Iterate quickly and automate phoneme overrides for high-risk content. Try hands-on testing with a trial account from your chosen TTS provider to confirm fit before scaling.
What is phoneme TTS (and IPA control) in plain language?
Phoneme TTS means giving a speech engine phonetic building blocks, not just normal spelling. By sending phonemes or IPA symbols, you tell the system exactly how words should sound. That extra control helps neural voices match a target pronunciation more reliably than relying on orthography alone.
What is a phoneme?
A phoneme is the smallest sound that changes meaning in a language, like the /p/ versus /b/ in "pat" and "bat". Phonemes are abstract labels for sounds, not letters. Different languages use different sets of phonemes, and one written letter can map to many sounds.
How IPA differs from normal spelling
IPA stands for International Phonetic Alphabet. It is a standardized set of symbols that represent speech sounds across languages. Unlike spelling, IPA shows exact sounds, so you can remove guesswork about stress, vowel quality, or consonant blends. That matters when a spelling rule would produce the wrong pronunciation.
Why modern neural TTS uses phonemes
Neural TTS models trained on phonemes get a direct link from input to sound. That reduces mispronunciations and makes accents, emphasis, and proper names predictable. Typical benefits include:
-
Higher pronunciation accuracy for names and technical terms.
-
Consistent brand voice across languages and locales.
-
Fine control over accent, stress, and timing for accessibility.
In short, phoneme-level input, often via IPA, lets teams move from guessing pronunciations to specifying them. For product teams localizing voice or requiring exact pronunciations, phoneme TTS is a practical way to hit the target more often.
Why phoneme control matters: pronunciation, trust, and accessibility
Phoneme-level control fixes the mispronunciations that cheapen voice output and confuse listeners. When you need exact names, technical terms, or mixed-language text, phoneme TTS gives you predictable phonetic output. It cuts post-edit cycles and keeps spoken content aligned with your brand voice.
Fix mispronunciations that break meaning
Orthographic TTS (text only) often guesses pronunciation from spelling. That fails on proper names, acronyms, product codes, and loanwords. Result: wrong word stress, swapped vowels, or an unintelligible reading. Those errors hurt comprehension and cause rework.
Common failure modes:
-
Names and places, especially non-native ones.
-
Abbreviations and model numbers like CX-9 or TTY.
-
Brand terms and invented words.
Protect brand voice and improve localization
Phoneme control forces consistent pronunciation across languages and regions. Localization teams can lock in a product name or tagline, then translate surrounding copy. That keeps the brand voice steady for global audiences. It also reduces review loops between linguists and engineers, speeding releases.
Support accessibility and assistive tech
Clear pronunciation is an accessibility issue, not just polish. The W3C's Web Content Accessibility Guidelines (WCAG) 2.0 include Success Criterion 3.1.6, which states,
Understanding WCAG 2.0: 'A mechanism is available for identifying specific pronunciation of words where the meaning of the words, in context, is ambiguous without knowing the pronunciation.' Proper phoneme marks make screen readers and other assistive tools read content correctly.
Bottom line: phoneme control prevents expensive mistakes, builds trust, and improves comprehension for everyone, including non-native speakers and users of assistive technologies.
Phoneme-level control solves the small pronunciation errors that break comprehension and trust. phoneme tts gives product teams a way to force exact sounds for names, brands, and technical terms. When a voice reads a wrong name, listeners pause, credibility slips, and support tickets rise.
Fix common failure modes
Orthographic TTS reads text like a person reads, and that causes errors. It confuses abbreviations, misreads proper nouns, and mangles loanwords. Use phoneme edits to fix those cases in a few steps, not a long QA cycle.
Common failure modes:
-
Letter-based spellings that yield wrong sounds
-
Acronyms pronounced as words instead of letters
-
Regional names rendered in the wrong accent
-
Brand names altered by silent letters or punctuation
Keep localization and brand voice consistent
Phoneme control helps you preserve brand pronunciation across languages. Localization teams can map local phonetics to the brand voice. That prevents awkward mistranslations and keeps tone consistent in ads, guides, and narrated tours.
Improve accessibility and assistive tech compatibility
Accurate pronunciation helps screen reader users and non-native listeners follow content. It reduces cognitive load and lowers misinterpretation risks for assistive tech. This approach aligns with accessibility goals such as clear, perceivable audio guidance used in guidelines like W3C WCAG.
In short, phoneme-level control protects comprehension and brand equity. It cuts rework, raises user trust, and widens accessibility. For teams localizing at scale, phoneme TTS is a practical tool to deliver reliable, inclusive audio.
How DupDub supports phoneme & IPA control (practical overview)
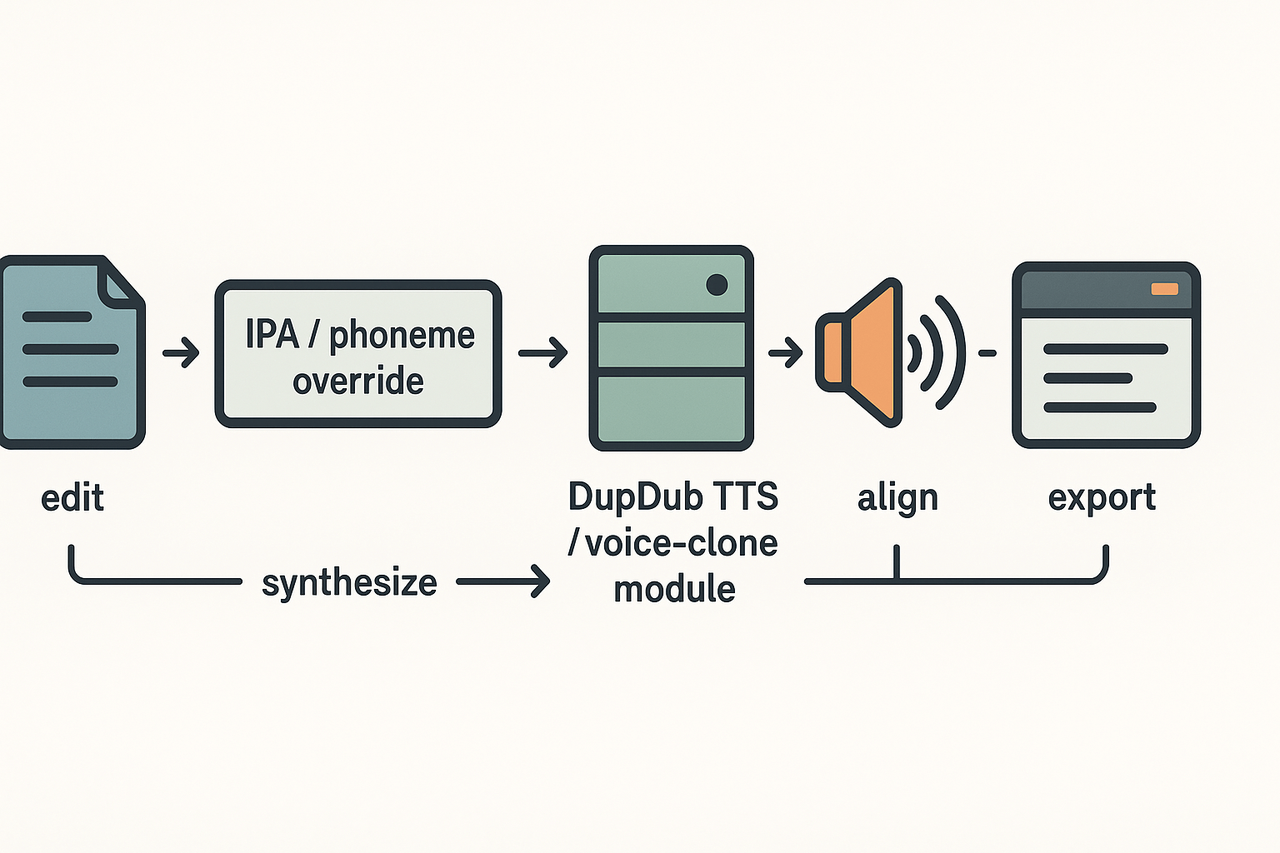
DupDub accepts phoneme overrides so you can lock in exact pronunciation at the syllable level. If you need precise control for names, technical terms, or place names, phoneme-level edits prevent mistranslation and improve listener trust. This page shows practical features, voice-clone behavior, and a sample API flow for pronunciation fixes when localizing content.
How DupDub accepts phonemes and IPA overrides
Upload plain text, or include IPA (International Phonetic Alphabet) or X-SAMPA phoneme tags inline. The editor accepts an override field per sentence or word, so the TTS engine uses your phoneme instead of its inference. Key features you’ll use:
-
An inline phoneme editor for single words.
-
Batch CSV import for many overrides at once.
-
Preview player with per-word highlighting.
Voice cloning and consistent phoneme behavior
Cloned voices preserve phoneme mappings across languages. When you clone a voice, DupDub stores the phoneme preferences applied during editing. That means a brand name edited in English keeps the same pronunciation when you clone that voice for Spanish or German output. For privacy, be aware of consent needs: The European Data Protection Board's
Guidelines 02/2021 on Virtual Voice Assistants emphasize that voice data, being biometric data, requires explicit consent from users under the GDPR.
Sample API flow for applying pronunciation fixes
-
POST source text to /transcriptions to get timestamps.
-
PATCH the transcription with a phoneme override field per word.
-
POST to /tts with {voice_clone_id, phoneme_overrides} to synthesize audio.
-
GET the aligned subtitles and confirm timing, then export MP3/WAV and SRT.
Each call accepts JSON with an array of {token, start, end, phoneme}. Use the preview endpoint to listen before exporting.
Practical tips for teams
Start with a short whitelist of high-impact terms, apply overrides, then scale via CSV. Automate step 2 in your CI pipeline if you localize at scale. Keep a shared glossary of phoneme entries so all cloned voices remain consistent across campaigns.
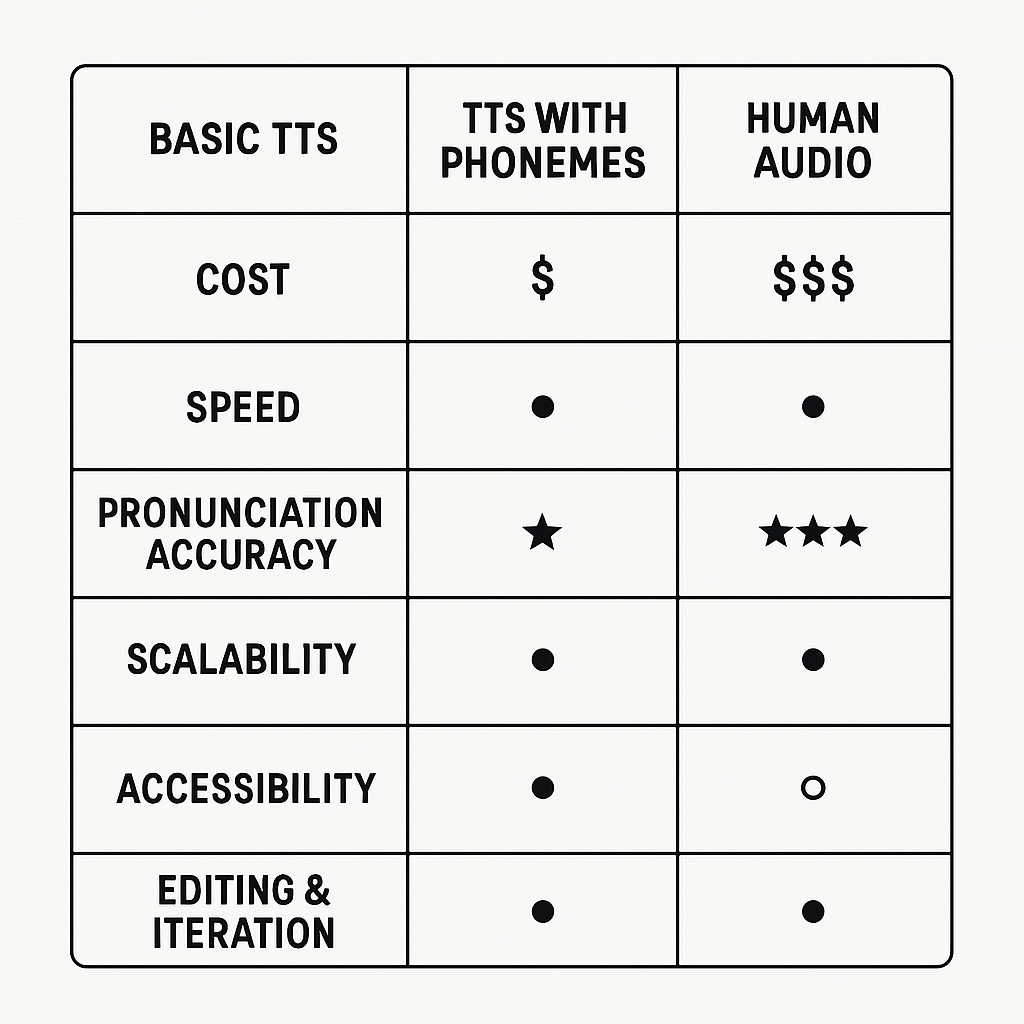
Side-by-side comparison: TTS vs TTS with phonemes vs human audio
Choosing the right voice generation method depends on factors like cost, time, pronunciation accuracy, and scalability. Below is a comparison chart that evaluates basic neural TTS, phoneme-augmented TTS, and recorded human audio across key attributes.
|
Attribute
|
Basic TTS
|
TTS with Phonemes
|
Human Audio
|
|
Cost
|
Low and predictable
|
Moderate (requires phoneme editing tools)
|
High (studio and voice talent fees)
|
|
Speed
|
Very fast
|
Fast, with extra prep for phonemes
|
Slow (scheduling and recording time)
|
|
Pronunciation Accuracy
|
Good for common words
|
Excellent for names, technical terms
|
Perfect (when performed by professionals)
|
|
Scalability
|
Excellent (batch processing possible)
|
High, with reusable phoneme rules
|
Limited (human time constraints)
|
|
Accessibility
|
Good for general use
|
Great for clarity and non-standard terms
|
Most natural, but hard to iterate
|
|
Editing & Iteration
|
Simple text changes
|
Quick with phoneme control
|
Costly (may require re-recording)
|
Guidelines for choosing:
Basic TTS is ideal when:
-
You need lots of content quickly.
-
Pronunciation doesn't need to be perfect.
-
The application is internal, like draft narration or mockups.
TTS with Phonemes is your best bet when:
-
Proper pronunciation of names, branding, and rare terms is critical.
-
You're producing audio for global audiences.
-
Consistency and automation are important.
Human Audio should be your choice when:
-
High emotional fidelity and nuance matter.
-
The project is high-visibility, like a commercial.
-
Legal and performance excellence are priorities.
In short, TTS variants are great for scalability and iteration, while human voice is unmatched in emotive delivery. Consider starting with phoneme-enhanced TTS, then elevate to human audio for signature content.
Accessibility & inclusivity: phoneme TTS for diverse audiences
Phoneme TTS gives you control over how words sound, which helps screen-reader users, second-language listeners, and anyone who needs precise intonation. Use phoneme edits and IPA (International Phonetic Alphabet) hints to fix names, technical terms, and regional pronunciations. That clarity boosts comprehension and trust for diverse audiences.
Multilingual projects: best practices
Plan pronunciation rules per language, not per file. Treat proper names, place names, and loanwords as exceptions. Test short, real phrases with native reviewers.
-
Create a pronunciation guide with phoneme or IPA entries for key terms.
-
Keep a central glossary so all voices and languages share fixes.
-
Use short, repeatable tests for each voice and accent.
Screen readers, hearing, and cognitive needs
Match speech rate and prosody to the user group. Slower pacing and clear breaks help people with cognitive load. For visually impaired users, prefer consistent pronunciation of landmark words like menu items or street names.
-
Lower speech rate by 5 to 10 percent for complex content.
-
Simplify sentence structure and add short pauses before lists or numbers.
-
Offer alternate layers: a phoneme-tuned narration and a faster summary version.
Phoneme-level control makes voice output clearer, more inclusive, and easier to localize.
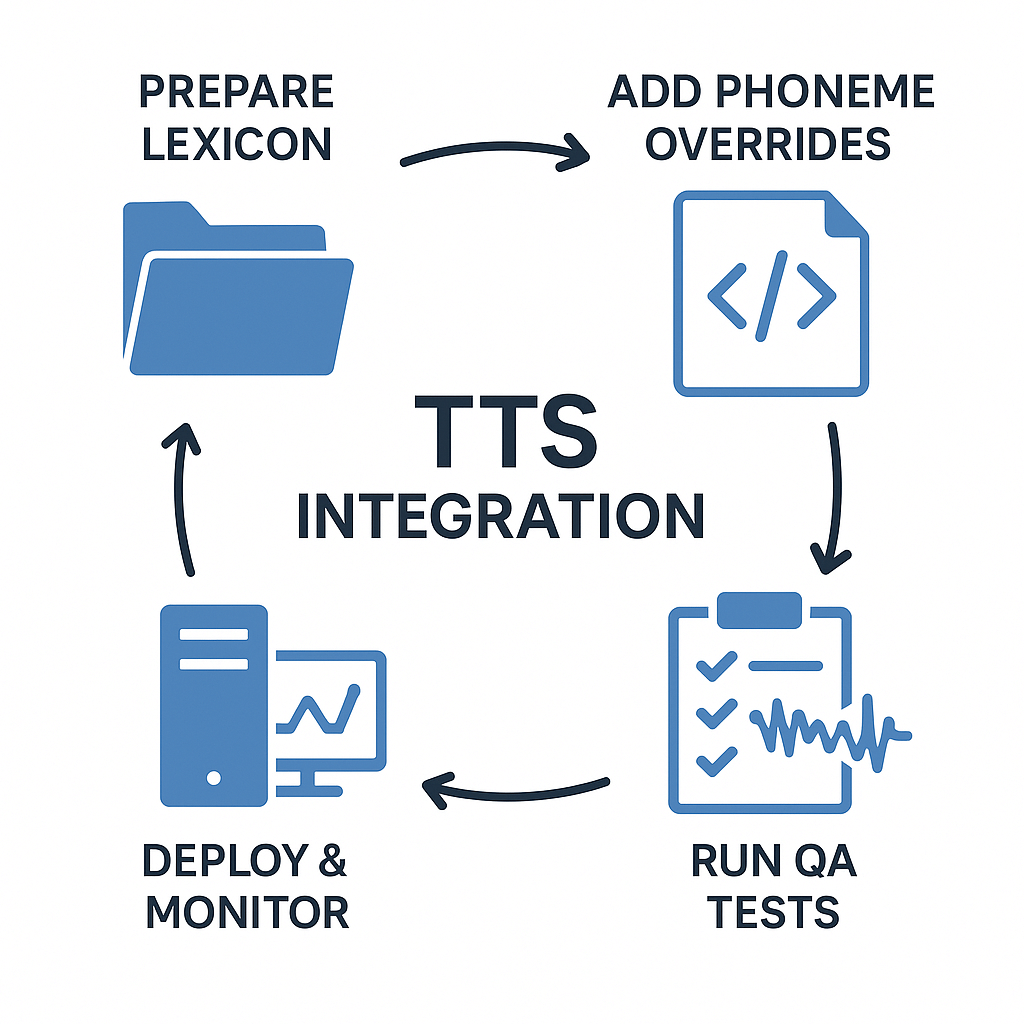
Implementation checklist & integration tips for product teams
Start practical work with a short pilot that validates phoneme TTS and IPA control (IPA is the International Phonetic Alphabet). Build a small test corpus that includes brand names, proper nouns, and common edge cases. Use phoneme overrides for known trouble words, and keep the pipeline repeatable so ringing errors are easy to reproduce.
Quick checklist
-
Prepare lexicon and style guide: collect names, acronyms, and local terms. Add IPA entries for ambiguous items.
-
Create test corpora: short scripts, long-form audio, and noisy examples. Include multilingual samples.
-
Add phoneme overrides to the content pipeline: store overrides as JSON or database fields, expose an IPA/phoneme field in your content API.
-
QA: run automated pronunciation checks, then record quick manual spot checks across voices.
-
Version & release: tag voice models and lexicon changes with semantic versions for rollbacks.
API and integration tips
-
Accept both plain text and phoneme fields in the same call, prioritizing phoneme input.
-
Map IPA to your TTS SSML or model phoneme parameter at the gateway layer.
-
Implement fallback logic: if phonemes fail, use the base grapheme text, log the case, and queue for lexicon update.
Ongoing maintenance
Run nightly regression tests after model updates. Keep a changelog for lexicon edits, and automate alerts for pronunciation drift. Small, frequent lexicon releases beat large, risky ones.
Real-world mini case studies & quotes (short examples)
Short, concrete examples show how phoneme-level control helps tourism, e-learning, and creator workflows. Below are three real-world style mini case studies that show fixes, outcomes, and short user quotes. These examples highlight why phoneme TTS matters when names, jargon, or brand voice must be exact.
Fixing local names at a museum
A city museum replaced clunky, anglicized pronunciations in its audio guide by adding phoneme edits. The tours now pronounce place names and donor surnames correctly. Visitors reported fewer interruptions and higher trust.
"We stopped getting correction notes after every tour. The names finally sound right." — Audio Lead, City Museum (anonymized)
Preserving technical terms in e-learning
An online training provider used phoneme edits to lock in product terms and model numbers. Learners heard consistent, repeatable pronunciations across modules. That cut revision cycles and helped non-native readers follow technical scripts.
"Phoneme control saved us hours of re-recording and kept subject matter experts happy." — Localization Manager, B2B E‑learning
Creator workflow: quick name fixes
A travel vlogger fixed regional names in minutes, keeping release cadence fast. Short phoneme tweaks avoided full re-dubs and kept the creator’s voice consistent across languages.
"Small phoneme edits, huge time savings." — Independent Creator
Expert line: A phonetics consultant says phoneme-level edits give product teams precise control over how a voice speaks unusual words, improving clarity and brand consistency.
Future trends, limitations, and troubleshooting matrix
Phoneme-level controls are becoming practical for production voices, and teams should plan for them now. phoneme tts lets you fix names, accents, and stress without re-recording or heavy post-editing. This section previews near-term features, lists current system limits, and gives a concise troubleshooting matrix for common QA failures.
Near-term trends
Labs are adding phoneme override flags and expressive labels to TTS APIs. Recent advancements show phoneme-level controls enable more precise manipulation of speech synthesis at the phonetic level, as surveyed in
Towards Controllable Speech Synthesis in the Era of Large Language Models: A Survey (2024), and vendors are exposing those knobs to developers. Expect better intonation templates, per-word stress control, and phoneme-timed prosody editing. These will speed localization and reduce costly human fixes.
Known limits today
Neural models still struggle with out-of-vocabulary names, regional allophones, and noisy input text. Very short samples can yield shaky voice clones, and aggressive pitch edits can sound synthetic. Latency and cost rise as you add fine-grained control, so plan QA gates accordingly.
Troubleshooting matrix
Use this quick table during QA to map issues to causes and fixes.
|
Issue
|
Likely cause
|
Quick fix
|
|
Mispronounced name
|
G2P (grapheme-to-phoneme) mapping error
|
Provide IPA override or phoneme sequence
|
|
Clipped vowel
|
Trimming or shortening the phoneme duration
|
Increase vowel length tag or add pause
|
|
Wrong stress pattern
|
Default lexical stress rules
|
Force primary stress (IPA or SSML)
|
|
Robotic or flat tone
|
Over-regularized prosody model
|
Apply the expressive prosody template
|
|
Inconsistent intonation
|
Mixed-language input or punctuation errors
|
Normalize text, mark language spans
|
Use this table as a release checklist entry. Add a phoneme QA pass for all named entities and local terms before launch.
FAQ — common questions about phoneme TTS and DupDub
-
How do I fix a mispronounced name using phoneme TTS?
You can correct names by supplying phonetic hints (IPA or simple phoneme spellings) for that token. In practice, add a short phoneme override in the input where the name appears, then preview and iterate until the pronunciation sounds natural.
-
Can I upload IPA directly to control pronunciation in phoneme TTS?
Yes, many neural TTS systems accept IPA (International Phonetic Alphabet) or phoneme sequences. DupDub supports phoneme-level overrides via its editor and API, so you can paste IPA for precise control.
-
Does phoneme control change cost or latency for phoneme TTS?
Phoneme overrides usually add negligible processing time and no per-request cost changes. The main cost factors remain voice quality, usage minutes, and API tier.
-
Can I send phonemes to DupDub via API for automated workflows?
Yes, DupDub’s API supports programmatic inputs, including phoneme hints and SSML-like tags, letting product teams automate pronunciation fixes at scale.
-
Who do I contact for trials, pricing, API docs, or enterprise support?
Next steps: start the 3-day free trial, view pricing, check the API documentation, or reach out to DupDub enterprise sales for custom SLAs and onboarding.



 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook