This guide explains when and how to add speaker diarization to a neural TTS and dubbing pipeline. It summarizes benefits, risks, and practical patterns so you can decide fast. Read it if you need to scale multi-voice dubbing or evaluate diarization for production use.
Key benefits: diarization turns mixed audio into labeled speaker segments, making it easy to map each voice to a cloned or synthetic speaker. That enables natural multi-voice blends, consistent character casting, and per-speaker prosody control. Expect tradeoffs: higher accuracy often means more compute and latency, overlap (simultaneous talk) needs special handling, and short snippets are harder to cluster reliably.
Practical integration notes: run diarization after a robust STT pass, use timestamps to align segments, then map speaker IDs to cloned voices before TTS or re-voice steps. In production, add confidence thresholds, a short human review loop for low-confidence regions, and metrics for diarization error, insertion, and overlap. The rest of the post gives tool comparisons, a mapping tutorial, a pipeline diagram, and a short case study to help you prototype quickly.
What is speaker diarization? A simple explanation
Speaker diarization is the process that answers "who spoke when" in audio. It splits a recording into time-stamped speaker segments, labeling each turn without transcribing the words or proving identity. Think of it as the timeline layer that sits alongside transcripts and speaker models.
Diarization versus ASR and speaker recognition
Automatic speech recognition (ASR) turns audio into text, it does not decide which speaker said each line. Speaker recognition (also called identification or verification) tries to link audio to a known identity, like matching a voice to a user account. Diarization sits between these tasks: it groups audio by speaker turns, producing segments that downstream systems use for transcription, cloning, or dubbing.
Key terms every engineer should share
-
Segment: a contiguous chunk of audio with a single dominant speaker. Segments have start and end timestamps.
-
Turn: a speaker’s speaking interval, often the same as a segment but sometimes multiple segments form a single turn.
-
Overlap: when two or more speakers talk at the same time. Overlap often causes the hardest errors.
-
Diarization error (DER): the standard metric. It sums missed speech, false alarms, and speaker confusions into one percentage.
What diarization produces in practice
A diarizer outputs a labeled timeline: start time, end time, speaker label, and sometimes a confidence score. Labels are usually anonymous (Speaker_1), unless you map them to known voices with speaker recognition. Quality varies by noise, channel, and overlap, so expect short misalignments in messy audio.
Why this matters for multi-voice TTS and dubbing
For multi-voice workflows, diarization provides the mapping from audio spans to speaker identities you want to clone. It ensures each spoken turn uses the correct synthetic voice and helps with timing and prosody alignment during re-voicing and multi-voice blending. Get this layer right, and downstream STT, cloning, and TTS integrate cleanly into scalable dubbing pipelines.
Why speaker diarization matters for neural TTS and multi-voice blending
Speaker diarization, which segments audio by who spoke when, is a force multiplier for neural TTS pipelines. It turns mixed, messy tracks into per-speaker clips you can clone, tune, and map to synthetic voices. That separation directly improves voice quality, prosody, and the viewer experience when you produce multi-voice dubs or narrated transcripts.
Concrete use cases where diarization pays off
Podcasts and interviews: Listeners expect a clear, consistent voice for each participant. Automated diarization extracts clean speaker turns so DupDub-style cloning produces distinct, repeatable voices. That keeps character identity steady across episodes.
Meetings and enterprise transcripts: Teams need searchable, speaker-labeled transcripts and native-sounding playback for summaries or translated highlights. Diarized segments let you feed only one speaker into cloning and TTS, reducing cross-talk and misattribution.
Multilingual dubbing and content repurposing: When you dub a multi-person video into another language, you want each on-screen speaker mapped to a single synthetic voice. Good speaker separation avoids voice bleed and makes blended mixes sound natural.
When automated diarization beats manual labeling
Automate when you have scale, short turnaround time, or lots of similar sessions. Automated diarization saves hours on multi-hour podcasts and hundreds of meetings.
Manual labeling makes sense for small, high-value projects where absolute accuracy matters. Use manual review when speakers overlap a lot, when legal transcripts are required, or when you must preserve nuanced speaker IDs.
Quick checklist:
-
Use automated diarization for volume and speed.
-
Add a manual pass for high-stakes, small-batch projects.
-
Prefer human review for heavy overlap or low audio quality.
How cleaner separation reduces cloning and mixing artifacts
Poor separation causes two big problems: voice contamination and wrong prosody. If a cloning model sees mixed audio, the speaker embedding picks up traits from others. That leads to muffled or gender-mixed results.
Clean speaker turns give stable embeddings, so cloned voices keep timbre and cadence. For TTS, precise segment boundaries improve alignment, yielding better stress and pauses. In blended dubs, this reduces phase issues and makes cross-fades sound natural.
Practical tips to reduce artifacts:
-
Remove overlapping speech or mark overlaps for special handling.
-
Use a short validation pass to re-clone any low-confidence speakers.
-
Normalize level and denoise before cloning.
-
Keep at least 20–30 seconds of high-quality audio per voice when possible.
Engineer tip: label overlaps explicitly, and treat them as special mix cases instead of forcing a single-voice assignment.
By mapping each speaker to a dedicated synthetic voice, you get more natural dubs, fewer cloning errors, and consistent brand voice across formats.
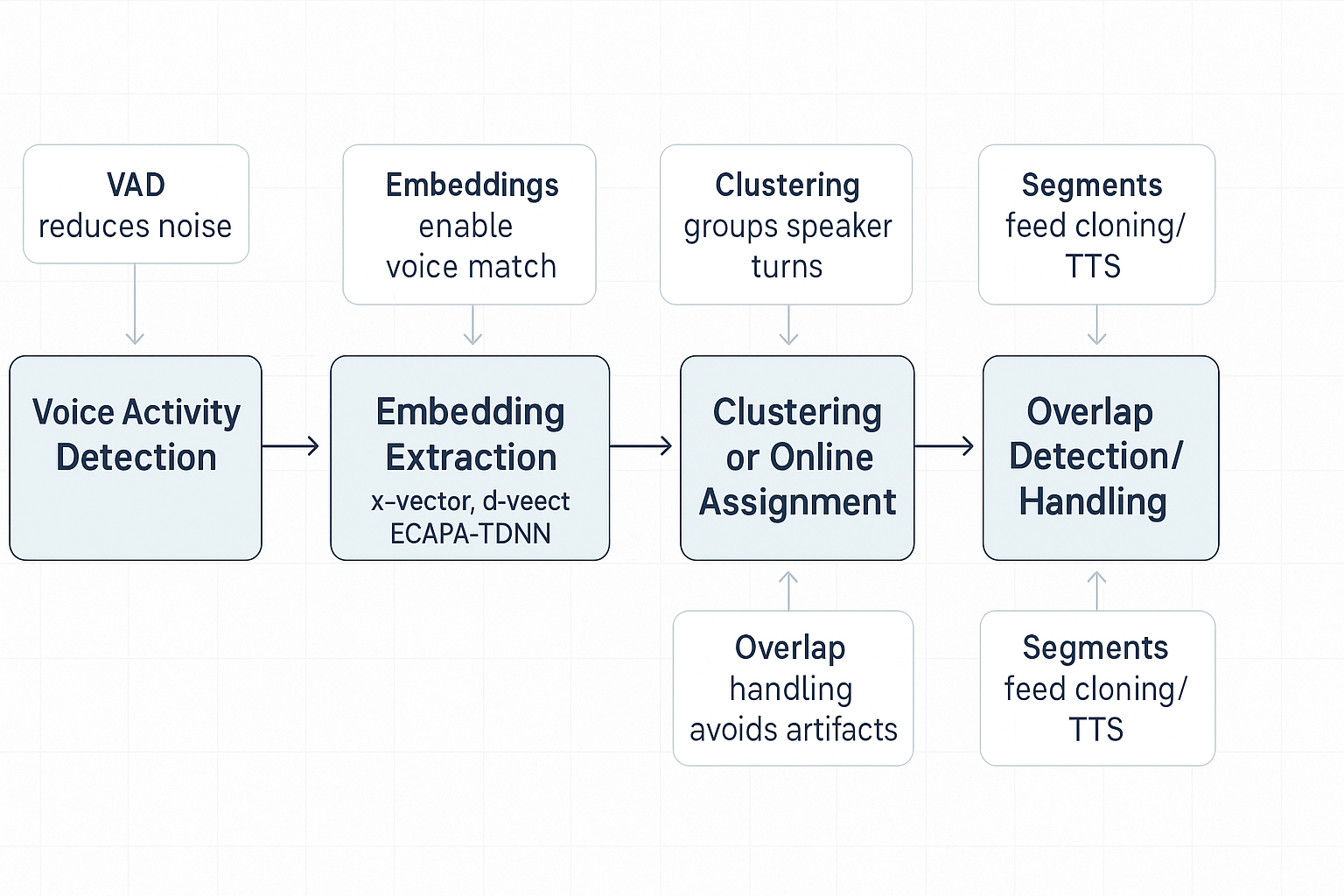
Typical diarization pipeline and key components
This section walks through a standard offline and online pipeline for speaker diarization, and explains why each block matters to downstream neural TTS and voice cloning. You’ll see how voice activity detection, speaker embedding extraction, clustering or online assignment, and overlap handling shape segment quality and cloning accuracy.
Voice activity detection: cut audio into speech and non speech
Voice activity detection (VAD) finds speech regions. Clean VAD reduces false segments that feed into cloning and TTS, so models get only speech to analyze and synthesize. Poor VAD bloats processing time and injects noise into embeddings, which hurts voice match and prosody.
Common error modes:
-
False positives: label noise or silence as speech, degrading cloned voice quality.
-
False negatives: drop short turns, losing speaker context for TTS.
-
Smearing around boundaries: misaligned cuts cause wrong phonetic context for synthesis.
Embedding extraction: x vectors, d vectors, ECAPA TDNN
This step turns each short speech clip into a fixed vector that represents speaker identity. Robust embeddings let you match diarized segments to cloned voices. For short turns, pick architectures tuned for small input lengths: "The ECAPA TDNN model has demonstrated superior performance in short segment speaker verification tasks, particularly for input lengths of 2 seconds or shorter on the VoxCeleb dataset,"
Short-segment speaker verification using ECAPA-TDNN with multi-resolution encoder (2023).
Why it matters to TTS: better embeddings mean more consistent timbre when mapping segments to voice clones. If embeddings drift, synthesized speech will sound inconsistent across turns.
Common error modes:
-
Short turn confusion: embeddings from <1 second of speech lack stable identity cues.
-
Channel mismatch: different microphones or compression change embedding space.
-
Speaker drift: gradual change in embedding for the same speaker over a long session.
Clustering or online assignment: group speakers and label segments
Offline diarization uses clustering to group embeddings by speaker. Online systems assign new embeddings to existing speaker profiles in real time. Good clustering yields clean per‑speaker tracks for batch TTS. Online assignment supports live dubbing and fast turnaround.
Why it matters to TTS: accurate grouping ensures each cloned voice receives all utterances for that speaker, preserving narrative flow and persona. If clustering merges speakers, the dubbed output blends voices incorrectly.
Common error modes:
-
Overclustering: one speaker split into many clusters, creating voice inconsistency.
-
Underclustering: distinct speakers merged, causing voice swapping.
-
Assignment latency: online systems mislabel brief turns during fast speaker changes.
Overlap detection and handling: detect simultaneous talk
Overlap detection flags regions with two or more active speakers. Handling overlaps is critical for natural dubbing and for deciding which voice to synthesize. Strategies include masking one speaker, generating blended output, or marking overlap for manual review.
Why it matters to TTS: overlapping speech can introduce artifacts and wrong speaker synthesis. If you ignore overlap, cloned voices will cut in and out or talk over each other in the final dub.
Common error modes:
-
Missed overlap: leads to abrupt speaker cuts in the final audio.
-
Incorrect dominance selection: picks the wrong speaker to synthesize in mixed segments.
-
Poor segmentation in overlap regions: makes alignment with subtitles and video harder.
Summary checklist:
-
Use robust VAD tuned for short turns.
-
Prefer ECAPA TDNN or modern embeddings for short-segment stability.
-
Choose offline clustering for batch accuracy, online assignment for low latency.
-
Treat overlap as a first class output, not a postprocessing afterthought.
Start here with a short summary that helps engineers choose the right diarization stack. This section compares leading open source and cloud diarization options by accuracy, latency, overlap support, and cost. It maps each tool to common workloads: low latency streaming, high accuracy offline batches, and hybrid flows that feed DupDub STT and voice cloning.
Quick state of the field
Ranked comparison table
|
Tool
|
Type
|
Typical accuracy (DER)
|
Latency
|
Overlap support
|
Best for
|
Cost notes
|
|
Pyannote
|
Open source
|
6–12% (varies by model)
|
Medium
|
Good
|
Offline batches, research
|
Free code, compute cost for training
|
|
Kaldi components
|
Open source
|
8–15%
|
High (offline)
|
Limited to moderate
|
Custom pipelines, heavy tuning
|
Free code, high engineering cost
|
|
NVIDIA NeMo
|
OSS + SDK
|
5–10% (GPU)
|
Low–Medium
|
Good with overlap models
|
On-prem GPU, hybrid
|
GPU cost, enterprise support
|
|
AssemblyAI
|
Cloud API
|
8–14%
|
Low
|
Limited to good
|
Fast API-driven workflows
|
Per-minute pricing, predictable
|
|
Deepgram
|
Cloud API
|
7–12%
|
Low
|
Strong for overlap
|
Real-time streaming, scaling
|
Usage pricing, competitive
|
|
Speechmatics
|
Cloud API
|
9–15%
|
Low
|
Moderate
|
Language coverage, enterprise
|
Usage pricing, tiered plans
|
Notes on the table: numbers are typical ranges. Real results depend on audio quality, languages, and overlap. Use this table as a starting point for tests on your data.
How to pick by workload
-
Low latency streaming: pick cloud APIs or GPU-accelerated SDKs. Deepgram and NeMo both support real-time streams with low lag. You sacrifice some raw accuracy for speed.
-
High accuracy offline batches: use Pyannote or Kaldi-based pipelines. They let you run heavy clustering and resegmentation passes. Expect longer runtimes but better DER on complex meetings.
-
Hybrid flows feeding DupDub: run fast cloud diarization for live previews, then re-run an offline pipeline for final rendering. Use DupDub’s STT and voice cloning to attach high-quality TTS after diarization.
Tradeoffs at a glance
-
Accuracy vs latency: lower latency means simpler models and higher error. If final quality matters, run an offline pass.
-
Overlap handling: models differ a lot. Modern neural diarizers and audio-visual systems handle overlaps best.
-
Cost vs control: open source gives control but needs engineering. Cloud APIs give fast results but costs scale with minutes processed.
Engineer tip: always run a short A/B test. Try a cloud API and an open source pipeline on 10 real files. Measure DER, speaker label stability, and downstream TTS quality. That will reveal whether you need fine-tuning, extra training data, or a multimodal approach.
If you want a tested hybrid recipe that pipes diarized segments into DupDub’s STT and voice clone modules, the next section shows a lightweight, code-light mapping tutorial.
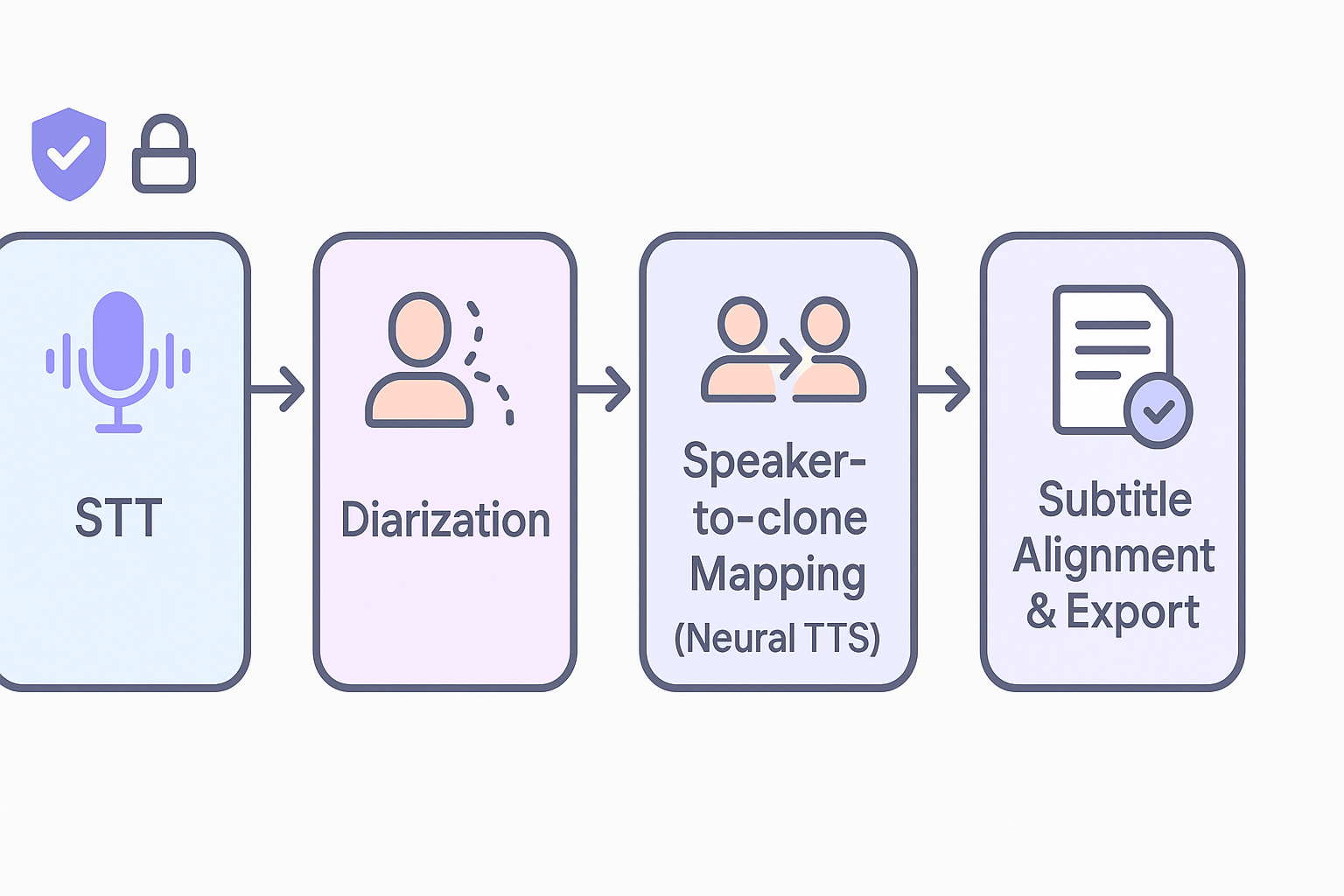
Start here with a simple, practical view of how speaker diarization plugs into DupDub’s end-to-end dubbing stack and why it matters for multi-voice workflows. At the front of the pipeline, automatic speech recognition splits audio to text and timestamps. Next, diarization separates who spoke when, creating labeled segments we can map to cloned voices. That mapping is the key to producing natural, multi-voice dubbed output at scale.
The pipeline is linear and modular, so teams can swap components. Typical flow:
-
STT (speech to text): generate transcripts and time-aligned word timestamps.
-
Diarization: assign speaker labels to timestamped segments.
-
Speaker-to-clone mapping: link each label to a synthetic voice profile.
-
Neural TTS / voice cloning: synthesize each segment in the target language or voice.
-
Subtitle alignment and export: stitch audio back to the video with captions and SRT/MP4 output.
Each step emits structured metadata. DupDub uses that metadata to auto-fill voice selections, preserve timing, and reduce manual syncing.
Practical mapping strategies for multi-voice dubbing
Map strategies depend on asset type and fidelity needs. Use one of these common approaches:
-
One-to-one mapping: create a clone for every diarized speaker. Best for interviews and branded shows.
-
Persona grouping: map several minor speakers to a small set of neutral clones to reduce cloning cost.
-
Priority cloning: clone only speakers above a duration threshold, fallback to high-quality generic voices for short guests.
Mapping rules to implement in code or orchestration:
-
Use diarization confidence scores to gate cloning. Only clone speakers with >X minutes and average confidence >Y.
-
Persist speaker identities across episodes with hashed metadata, not raw audio.
-
Provide a manual override UI for ambiguous or merged labels.
These tactics let you balance cost, voice consistency, and turn-around time.
Handling short turns, rapid exchanges, and overlap
Short turns and overlaps are the hardest parts. Here’s how to handle them robustly:
-
Merge adjacent segments under a short-duration threshold if the same speaker label repeats. This reduces choppy TTS output.
-
For overlapped speech, render parallel stereo tracks or choose the dominant speaker by energy or diarization confidence.
-
When neither speaker dominates, synthesize a short blended cross-fade using the two mapped voices to preserve conversational flow.
Operational tip: label segments with a minimum duration for cloning. Cloning a speaker from a single 2-second line rarely produces credible results, so automate fallbacks.
Alignment and export: keeping timing natural
Preserve natural pacing by respecting original word timing and pauses. DupDub’s subtitle alignment takes input timestamps and adjusts synthetic audio to match on-screen lips and captions. Best practices:
-
Use word-level timestamps to stretch or compress synthetic speech within a 20 to 30 percent window.
-
Keep breaths and short pauses at original positions to retain natural cadence.
-
Run a quick QA pass on sentence-level sync, and only then finalize exports to MP4 and SRT.
Automation note: DupDub can auto-suggest timing edits, but always allow a visual timeline for final tweaks.
Privacy, consent, and production controls
Design consent flows before cloning or storing voice data. Under the GDPR, consent must be freely given, specific, informed, and unambiguous, provided through a clear affirmative action, as noted by
European Commission (2025). In practice:
-
Store only derived embeddings or hashed IDs, not raw source audio, when possible.
-
Lock cloned voices to the original speaker account and require explicit reconsent for reuse.
-
Log consent records with time, asset ID, and the consent text used.
Engineer tip: build consent checks into the pipeline entry point so no downstream service can synthesize a voice without a recorded approval.
Why this reduces manual work
Diarization plus automated mapping eliminates much of the tedious manual voice assignment and timing work. By combining diarized labels, cloned voice profiles, and subtitle alignment, DupDub lets teams produce multi-voice dubs with fewer manual edits and faster turnaround. The result is scalable localization that preserves speaker identity and runtime privacy controls.
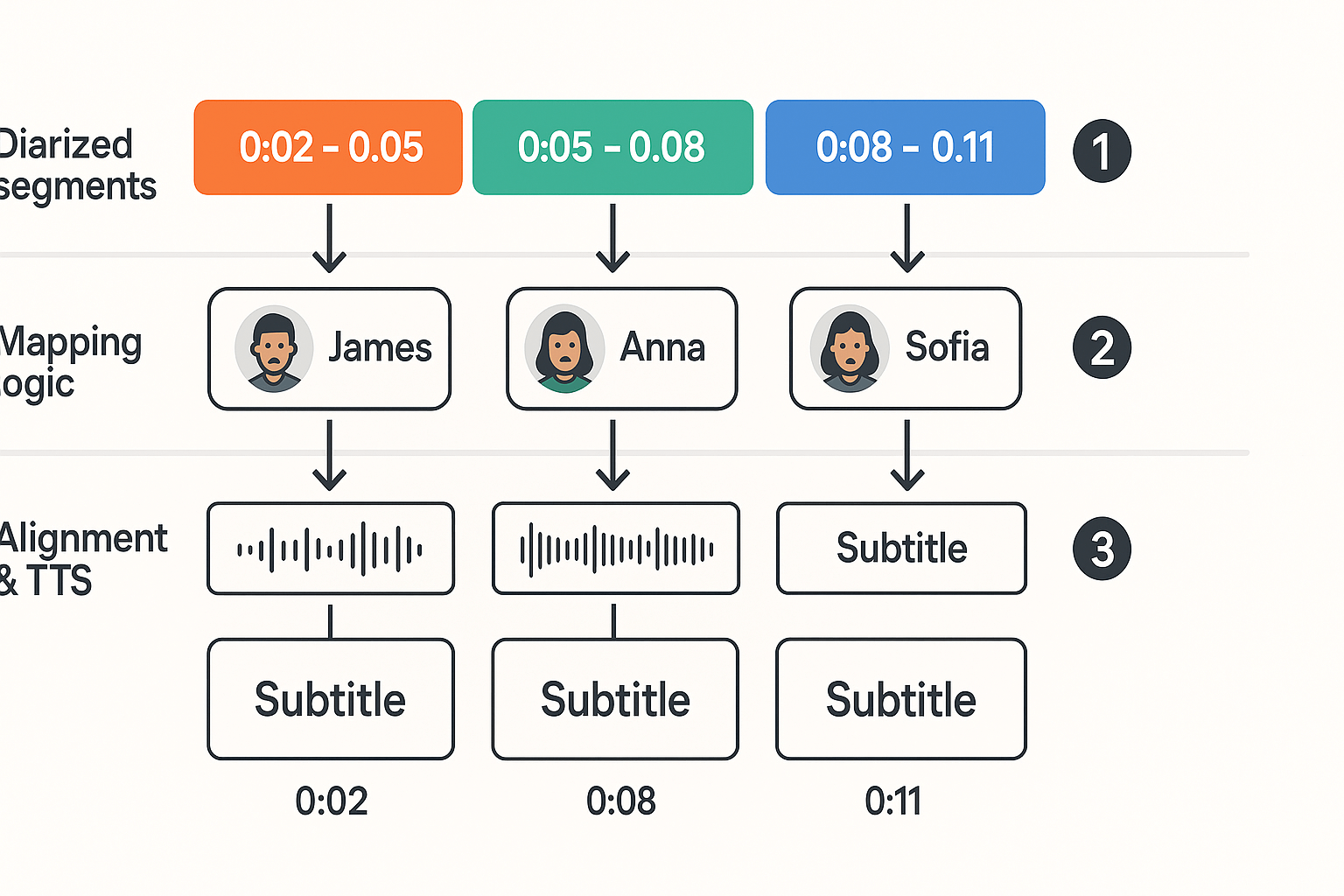
Step-by-step tutorial: map diarized speakers to cloned voices in practice
This compact tutorial shows how to turn diarized audio into a multi-voice dubbed output you can generate at scale. We start with diarized segments and transcripts, assign cloned voices with clear fallback rules, then align text to timestamps for subtitle timing. Follow these practical steps to reduce artifacts and automate mapping with DupDub.
Step 1: prepare diarized segments and transcripts
Export diarization output as a TSV or JSON with start, end, speaker_id, and confidence. Keep a separate transcript with sentence-level timestamps from STT. If timestamps are word-level, collapse to sentence blocks. Clean up obvious errors: merged overlapped speech into short runs, and trim silence at segment edges by 50–200 ms.
Step 2: label and consolidate speaker clusters
Map diarization clusters to canonical speaker labels used by your product. If clusters are noisy, run a simple merge pass: join clusters with high cosine similarity in embedding space and high turn adjacency. If you have ground-truth samples for key speakers, assign them first. Use the phrase speaker diarization output confidence to flag low-quality clusters for manual review.
Step 3: assign voice clones with fallback rules
Create a mapping table: speaker_label -> preferred_clone_id. Apply these rules in order:
-
Exact match: assign a clone trained on that speaker, if available.
-
Voice family match: match by gender, pitch range, or style tag.
-
Language match: pick a clone that supports the target language.
-
Fallback neutral: use a neutral TTS voice when no clone fits.
For short or low-confidence turns under 350 ms, force the fallback neutral voice to avoid artifacts.
Step 4: align transcripts to audio timestamps for subtitles
Use the sentence-level timestamps to build subtitle cues. For each diarized segment, clip transcript text to fit the segment times. If turns overlap, choose the dominant speaker by energy or confidence. Stretch or compress subtitle display time proportionally to word count, but cap frame length between 1 and 7 seconds for readability.
Step 5: generate TTS with prosody and crossfade rules
Synthesize each mapped segment independently, but apply these post-processing steps:
-
Trim leading/trailing silence in the TTS output by 40–120 ms.
-
Apply 20–60 ms crossfades between adjacent segments from the same voice to hide cut artifacts.
-
For speaker changes, insert a short fade-out plus a 30–80 ms fade-in to preserve natural breath timing.
-
Match speaking rate and intonation tags when you can. If your clone supports style tokens, prefer them for questions vs statements.
Practical tips to reduce artifacts
-
Short-turn heuristic: merge consecutive turns shorter than 500 ms if they belong to the same speaker. This reduces chopped prosody.
-
Prosody matching: use a lightweight pitch/time estimator from the original audio and nudge TTS rate to match median pitch.
-
Loudness normalization: LUFS normalize per-speaker to keep volume stable across voices.
DupDub integration points for automation
-
Use DupDub STT to get aligned transcripts, then import diarization segment JSON for mapping.
-
Push the speaker->clone mapping table to DupDub API for batched TTS generation.
-
Automate subtitle export (SRT) from the aligned timestamps and programmatically stitch audio and video via the DupDub video API.
Engineer tip: failure modes to watch
If a speaker keeps being split into many clusters, lower the clustering threshold and prefer embedding similarity over short adjacency rules. If cloned voice artifacts appear, try longer context windows when cloning or force a neutral fallback for very short segments.
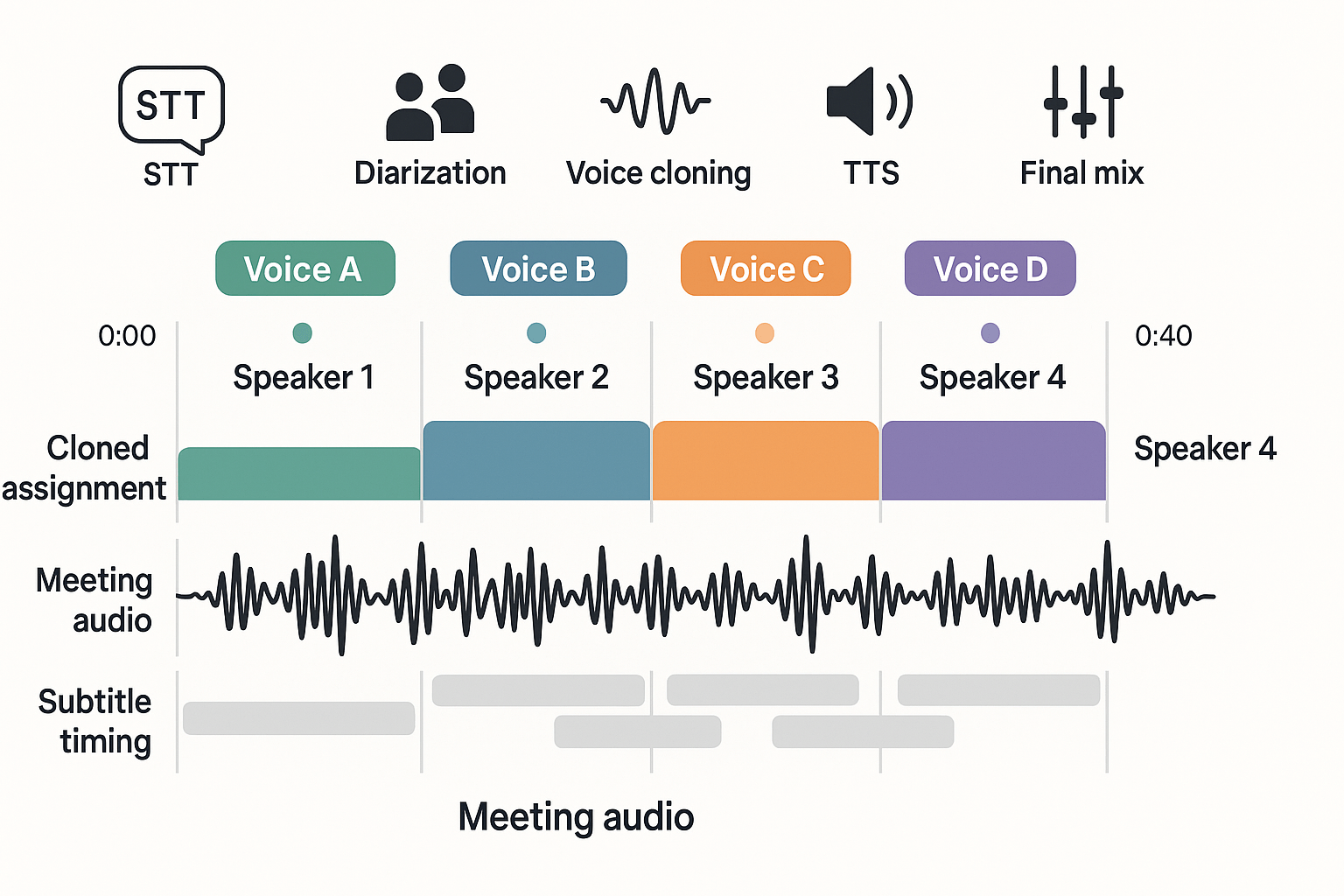
Real-world case study: meeting audio → multilingual dubbed video with multi-voice blending
We converted a 45 minute product review meeting into a multilingual dubbed video with distinct speaker voices. The project started with speaker diarization (speaker segmentation) to split the meeting into who-spoke-when. This first step let us map each speaker to a cloned voice, keep turn order, and preserve conversational pacing in the target languages.
Problem and dataset
The audio came from a hybrid meeting, recorded on laptop mics and a room system. Four active speakers spoke intermittently, with a few overlaps and background noise from typing. Transcripts were noisy in noisy segments, so we needed robust segmentation before cloning and dubbing.
Diarization choices and pipeline
We compared two options: an automated neural diarizer tuned for short turns, and a conservative clustering approach that merges short segments. We used automated diarization to get a fast baseline, then applied a rule-based postprocess to merge sub-1s fragments. The pipeline order was: STT, diarization, segment-level QA, voice assignment, TTS rendering, subtitle alignment, and final mix.
Step-by-step mapping to DupDub voice clones
-
Export time-aligned segments (start/end, speaker id).
-
Normalize segment audio, then attach transcript snippets.
-
For each speaker id, create or select a DupDub voice clone that matches timbre and cadence.
-
Apply a confidence threshold: auto-assign clones when diarization confidence ≥0.85. Low-confidence turns went to a pooled generic voice for review.
-
Generate per-language TTS tracks, keeping original pause lengths for natural pacing.
This strategy kept most of the work automated, while making manual review efficient.
Timing, blending and multilingual timeline
We preserved original timing by mapping segment durations to TTS output. For long turns, we split on breath or punctuation to reduce synthetic monotony. For overlaps, we layered two voices with a slight ducking (lowering volume on the shorter segment) to keep clarity. Subtitles were produced from the cleaned transcripts and aligned to the cloned audio for each language.
Outcomes, lessons learned and engineering notes
Measured outcomes: automated pipeline reduced turnaround time by 60 percent and cut dubbing costs heavily. Diarization errors clustered in overlaps and short backchannels, so manual fixes saved the most time when focused there. Key lessons:
-
Accept imperfect segmentation for low-importance filler (uh, mm) and allocate review time to mid-length turns.
-
Use a high-confidence auto-assign threshold to avoid mis-voicing.
-
Blend overlapping speech with ducking rather than forced merge.
Engineer tip: "If you get many sub-1s fragments, add a windowed merge step before voice assignment; it reduces false speaker switches fast."
This case shows how practical diarization choices make multi-voice dubbing scalable while keeping quality high.
Challenges, evaluation metrics and ethical considerations
This section covers the metrics teams should track, common failure modes and mitigation steps, and the privacy, consent, and bias risks that come with cloning voices and revoicing across languages. It focuses on practical checks and monitoring that engineering and product teams must run before wide release. Keep these guidelines nearby as a checklist during build and launch.
Key metrics to track
Start by instrumenting objective diarization and downstream quality metrics. Track these regularly, and review them alongside user feedback.
-
Diarization Error Rate (DER): measures time-aligned errors from missed speech, false alarms, and speaker confusions. Lower is better, and it’s your core system health metric.
-
Jaccard Error Rate (JER): measures overlap-based segment mismatch, useful when overlap is common. Use it to diagnose segmentation problems.
-
Speaker F1 (identification): precision and recall for speaker labels, helpful for tracking labeling quality across clusters.
-
Cluster purity and NMI (normalized mutual information): measure how well embeddings group the same speaker. Use them to tune clustering hyperparameters.
-
Downstream WER (word error rate): report ASR accuracy on diarized segments, since ASR errors amplify TTS mistakes.
-
Perceptual MOS or MUSHRA for TTS: periodic human listening tests to rate naturalness and speaker similarity. Automated metrics are useful, but human scores catch artifacting.
Common failure modes and mitigations
Diarization systems fail in predictable ways, and each needs a targeted fix. Below are typical failure modes and practical mitigations.
-
Overlap and crosstalk: overlapping speech causes label collisions. Use overlap detection, separate overlapping segments, or targeted overlap-aware models.
-
Short or single-word turns: embeddings are unreliable on very short segments. Apply length thresholds and re-segmentation heuristics.
-
Channel and noise mismatch: different mics or codecs break models. Add augmentation, domain-specific fine tuning, or per-channel normalization.
-
Speaker drift and cluster fragmentation: long sessions can create many clusters. Use speaker embedding smoothing and dynamic reclustering.
-
Accent and language mismatch: embeddings trained on one language may fail on another. Retrain or adapt embeddings on multilingual data.
Engineer tip: log example failures with timestamps and audio clips. That speeds root cause analysis.
Privacy, consent and bias risks
Handling voice data raises legal and ethical questions that product teams must address proactively. Require explicit, auditable consent before creating voice clones, limit retention, and lock clones to their source policy by default. Also document your biometric handling practices, for example consult
ANSI/NIST-ITL 1-2011 Update:2013, which includes the full integration of supplemental information defining voice and dental records, when designing secure storage and access controls.
Bias risks include underperformance for accents, age groups, and low-resource languages. Mitigate bias by expanding training sets, running stratified evaluations, and including human reviewers from affected groups.
Production monitoring, human-in-the-loop QA and compliance checks
Before wide release, implement both automated and human checks. Use these steps as a minimum compliance checklist.
-
Pre-release audit: confirm consent logs, data minimization, and legal signoff.
-
Metrics dashboard: surface DER, speaker F1, downstream WER, and MOS trends with alerting on regressions.
-
Sample-based human QA: daily or weekly listening checks for fluent speech and speaker alignment.
-
Security and access reviews: ensure encrypted storage and role-based access to voice clones.
-
Fairness audits: run stratified tests across accents and languages, and document residual gaps.
-
Rollback and abuse response: publish a clear rollback plan and takedown process for misuse.
Treat the system as a socio-technical product, not just a model. Combine automated monitoring with human review and legal oversight before scaling publicly.
FAQ — common questions people ask about diarization & DupDub workflows
-
How accurate is speaker diarization on noisy audio for neural TTS workflows?
Noise hurts most diarization systems, but you can get good results with the right prep and models. Use denoising, voice activity detection (VAD), and robust embeddings (x-vector or ECAPA-TDNN) before clustering. See the step-by-step tutorial above for practical tips and scripts to test on noisy meeting files. Try the 3-day free trial to evaluate accuracy of your data.
-
How do you preserve speaker identity across languages when cloning voices for dubbing?
Preserving identity means cloning timbre and speaking style, then mapping diarized segments to those clones during rendering. The tutorial shows how to link each diarized speaker to a voice clone and add prosody adjustments for natural results. For high-volume work, request a demo to review multilingual cloning and identity checks.
-
How does diarization handle overlapping speech and cross-talk in multi-speaker audio?
Overlap is the hardest case. Modern pipelines add overlap detection, speaker-attributed ASR, or source separation (speech separation) to isolate channels. You can also blend voices when overlap is short, or pick the dominant speaker for clarity. See the meeting-to-dub case study above for real-world choices and tradeoffs. Start the free trial to try multi-voice blending on your files.
-
What privacy safeguards does DupDub use for voice cloning and diarization?
DupDub keeps cloned voices locked to the original speaker, uses encrypted processing, and offers GDPR-aligned controls for enterprise reviews. Don’t send sensitive data without first checking policies; contact sales for custom data handling and on-prem or VPC options. Reach out to sales for an enterprise review.
-
How can I try DupDub: trial, demo, or enterprise review for production workflows?
You can start with the 3-day free trial to run the tutorial end-to-end on your files. If you need a walkthrough, request a personalized demo, or contact sales for compliance and scale planning. Each path maps back to the tutorial and case study so you can reproduce the steps on your content.


 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook