

-
Day 1 quick wins
-
Enable TCP keepalive and HTTP/2 or gRPC, reuse TLS sessions.
-
Test Opus or low-latency PCM, and enable streaming responses.
-
Run a 5-minute p95 latency test over your typical network.
-
-
Week 1 sprint
-
Add model-side streaming and chunked synthesis.
-
Reduce text preprocessing and batch sizes.
-
Run controlled A/B tests, collect p50/p95/p99 and Jitter.
-
-
Quarter plan
-
Deploy regional or edge inference, prewarm instances.
-
Re-architect buffering and adaptive jitter buffers.
-
Track cost versus latency, and set SLOs (service level objectives).
-
-
Measure end-to-end time from request to first audio byte.
-
Compare streaming vs non-streaming under packet loss.
-
Automate nightly benchmarks to detect regressions.
What is TTS latency, and why does it matter for real-time synthesis
Breakdown of delay sources
-
Microphone capture and pre-processing: Capturing audio includes ADC conversion and voice activity detection. If you use client-side noise suppression or echo cancellation, those add small delays.
-
Network transport: Packets travel to and from servers, and may queue at routers. Mobile and Wi-Fi links have variable jitter and can double the end-to-end delay.
-
STT and LLM processing: Speech-to-text (STT) or a large language model (LLM) may be used for intent or turn-taking logic. These compute stages can take tens to hundreds of milliseconds, depending on model size and batching.
-
TTS synthesis time: The TTS engine generates a waveform or vocoder output. Non-streaming synthesis blocks until complete, while streaming TTS emits audio progressively. Model complexity and token rate directly affect delay.
-
Audio pipeline and playback: Buffering, format conversion, and playback device latency matter. Many browsers and mobile players introduce 50 to 200 ms of buffering by default.
Human perception targets for conversational flow
-
<200 ms: ideal for audio feedback tied to immediate actions, like button clicks.
-
<500 ms: target for seamless turn-taking in dialogue, where users feel conversation is natural.
-
<1 s: acceptable for short system responses, though it may feel slightly slow.
-
1.5 s: likely to break the flow, causing users to interrupt or repeat themselves.
Common UX failure modes caused by high latency
-
Overlap: The system speaks while the user is still talking, causing interruptions and confusion.
-
Awkward gaps: Long silence makes the system feel slow or inattentive.
-
Repeated prompts: Timeouts cause retries, leading to duplicate audio or repeated instructions.
How to measure latency: metrics, tooling, and benchmark methodology
Core metrics to collect
-
Time-to-first-byte for audio (TTFB): time from request send to the first audio byte received.
-
First-audio-frame latency: time to the first playable audio frame decoded on the client.
-
End-to-end mouth-to-ear: from text input or play trigger to audible output start, includes TTS generation, transport, decode, and playback.
-
Jitter and packet loss: measure RTP/UDP jitter and packet loss per stream, and compute inter-arrival jitter.
-
p50, p95, p99, p999: report these percentiles for each metric and for combined mouth-to-ear.
-
Throughput and concurrency: requests per second, audio seconds generated per second, and CPU/GPU utilization.
How to tag traces across client, network, and server
Repeatable benchmarking methodology
-
Define test matrix: codec, sample rate, streaming vs non-streaming, regions, instance size.
-
Run warm-up runs to prime caches and models.
-
Execute steady runs at target load for 5 to 15 minutes, then burst runs with sudden spikes to observe tail behavior.
-
Collect at least 1,000 samples per cell for stable p99/p999 estimates.
-
Compare synthetic tests (controlled clients with network shaping like tc/netem) to production sampling (real clients via tracing and sampling).
Instrumentation and tooling
-
WebRTC internals: use the browser WebRTC stats API and about:webrtc logs. Note that Identifiers for WebRTC's Statistics API (2022) documents the totalProcessingDelay metric, which measures the sum of time each audio sample takes from RTP reception to decode. Use that metric to separate network vs processing delay.
-
Browser timing APIs: use PerformanceObserver and navigation/performance timing for rendering and decode events.
-
Prometheus and Grafana: export server and client metrics, create dashboards for p50/p95/p99/p999, and alert on p99 degradation. Follow official Prometheus exporter patterns for histogram buckets and labels.
-
Network tools: tc/netem for shaping, Wireshark/tcpdump for packet-level validation.
Network & transport optimizations for real-time synthesis
Pick the right transport: WebRTC, WebSocket, or HTTP/2
|
Transport
|
Handshake cost
|
Encryption
|
Best for
|
Notes
|
|
WebRTC (UDP)
|
Medium-high
|
DTLS/SRTP
|
Lowest steady latency
|
ICE adds setup RTTs, but packets avoid TCP delays
|
|
WebSocket (TCP)
|
Low
|
TLS over TCP
|
Simple bidirectional streams
|
Use TCP_NODELAY and keepalives
|
|
HTTP/2 (TCP)
|
Medium
|
TLS over TCP
|
Multiplexed requests
|
Good for batching, worse for tiny frames
|
Concrete fixes you can apply today
-
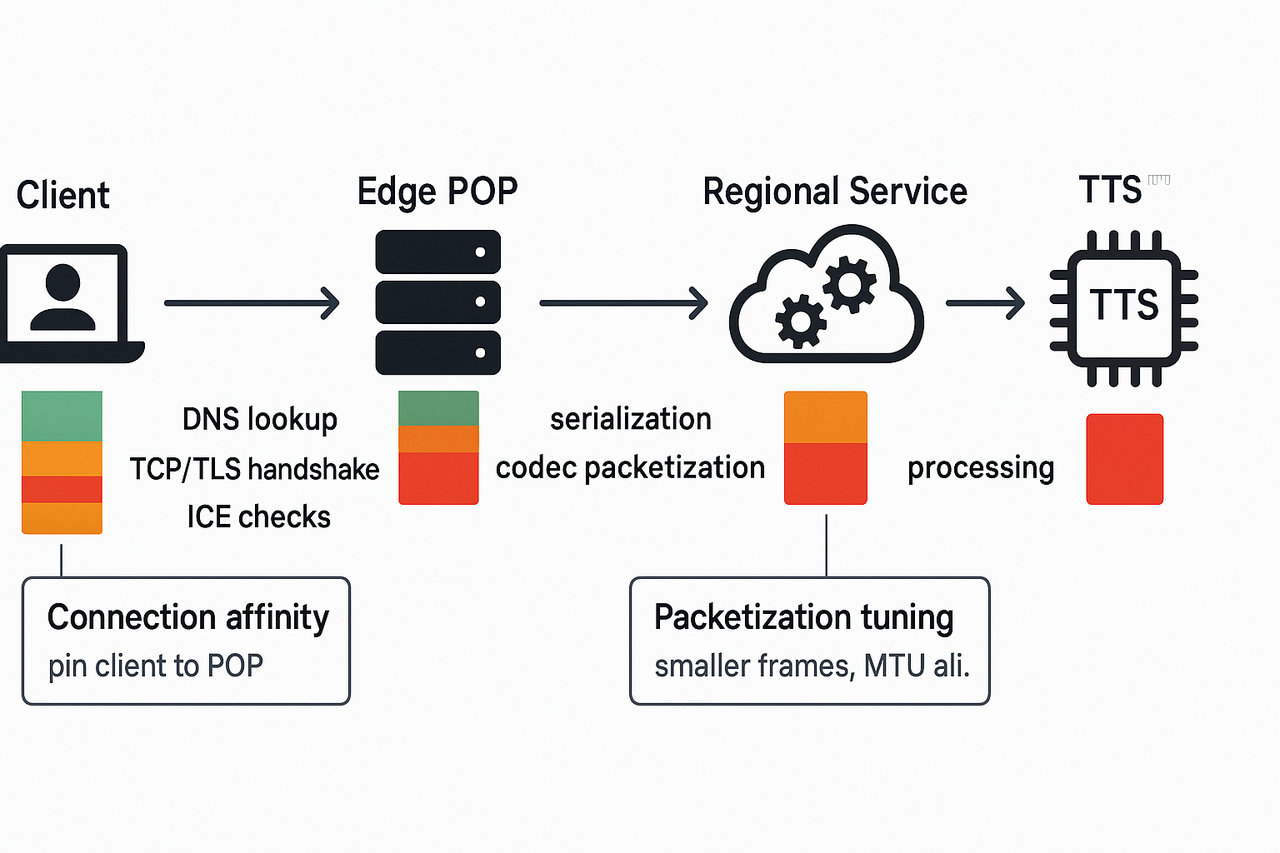
Reduce hops and RTT: use anycast edge POPs and route optimization. Less network distance cuts TTFB.
-
Keep connections warm: TLS session resumption, HTTP/2 connection reuse, and WebSocket keepalives avoid repeated handshakes.
-
Use connection affinity: bind a client to an edge or regional instance so TURNovers and repeated ICE are rare. That also improves caching and CPU locality.
-
Tune transport-level settings: disable Nagle (TCP_NODELAY), enable TCP Fast Open where possible, and set aggressive keepalive intervals.
-
Optimize MTU and packetization: match UDP/TCP MTU to avoid fragmentation, and packetize short audio frames tightly to reduce per-packet serialization delay. Smaller frames lower codec buffering, but raise packet overhead. Test the tradeoff.
-
Prefer UDP-based stacks for sustained low jitter: when NAT traversal succeeds, UDP avoids head-of-line blocking and reduces frame latency.
Edge, CDN, and routing patterns
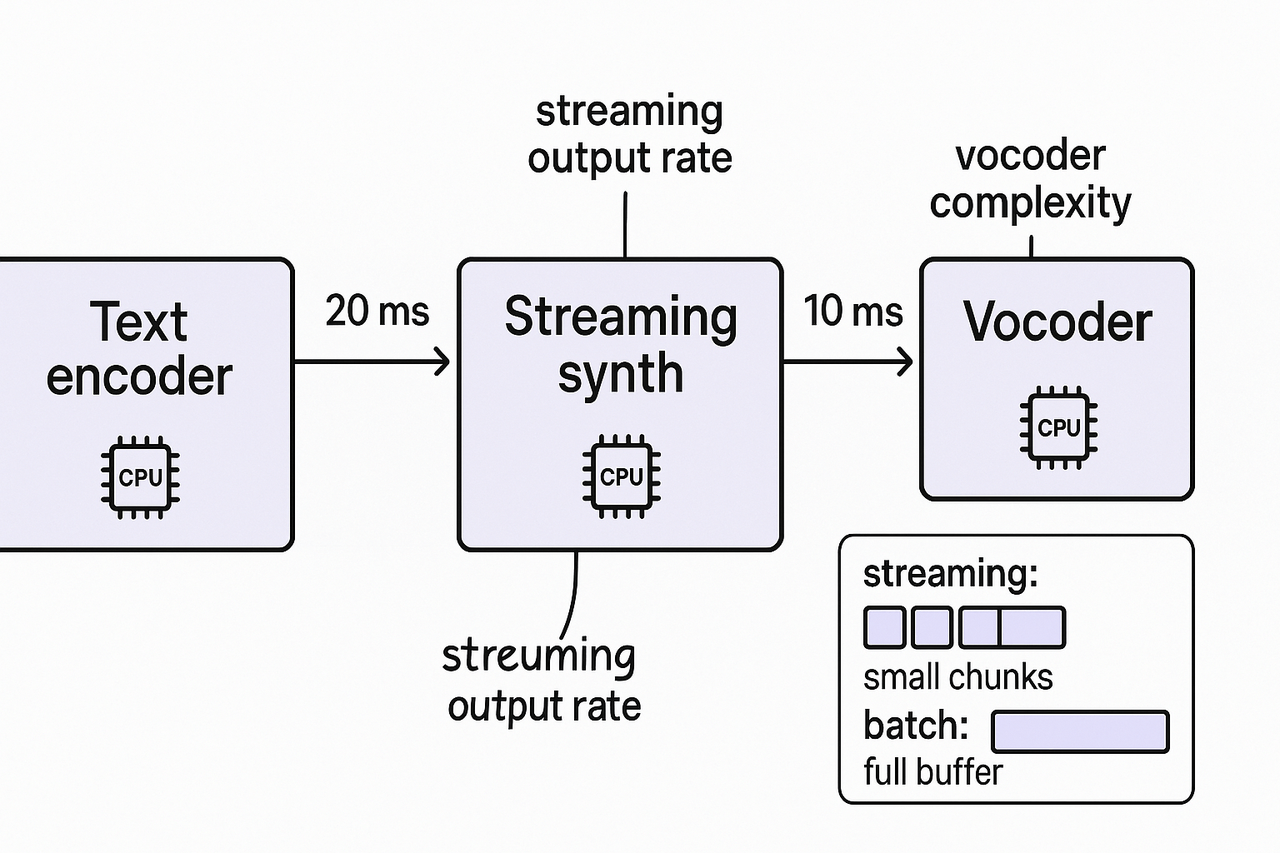
Model & inference optimizations (TTS engine, streaming vs non-streaming)
Streaming vs batch synthesis: rules of thumb
-
Choose streaming if end-to-end lag must be under 200 ms for short replies.
-
Choose a batch for prerecorded content that can tolerate 500 ms or more.
-
Hybrid: stream smaller turns, batch long segments to save compute.
Model-side levers you can control
-
Model size: Smaller models reduce compute time and cold-start latency. Choose compact TTS for short utterances. Larger models improve nuance but add latency.
-
Pruning and quantization: remove redundant weights and use INT8 or dynamic quantization to cut CPU cycles. Perceptual quality often stays high.
-
Batching window: batch small concurrent requests for GPU throughput, but keep the window tight. A 10-50 ms window balances latency and efficiency.
-
Concurrency limits: cap simultaneous inferences to avoid queuing delays. Prefer autoscaling pools with short warmup.
Vocoder choice and provider knobs to shave latency
-
Pick streaming endpoints with small chunk sizes.
-
Lower the sample rate to 22 kHz when 44.1 kHz is overkill.
-
Use low-latency vocoder presets if available.
-
Warm pools to avoid cold-starts and cache common phoneme outputs.
-
Reduce frame size and enable early audio flushing for partial plays.
Audio pipeline, buffering, and playback strategies
Minimal viable buffer and adaptive jitter buffers
Chunking frames versus continuous streaming
-
Chunked frames: send 20–40 ms frames. Benefit: quick playback start, easier partial-speech barge-in. Cost: more packets, slightly higher bandwidth overhead.
-
Continuous streaming: send a steady audio stream in larger blocks. Benefit: fewer context switches, lower packet overhead. Cost: longer time to first audible byte and heavier decoder work.
Client format, sample rate, and decoder cost
Partial-speech playback, barge-in, and turn-taking
Edge versus central-cloud: trade-off matrix
|
Deployment
|
Latency reduction
|
Incremental cost
|
Operational complexity
|
Privacy/data residency
|
|
Single central region
|
Moderate
|
Low
|
Low
|
Moderate, depends on the region choice
|
|
Multi-region cloud
|
Good
|
Medium
|
Medium
|
Better, regional controls available
|
|
Edge on-prem / PoP
|
Best
|
High
|
High
|
Best, full data residency
|
Where to place services, and why it matters
-
Place inference near the largest user cluster first.
-
Use multi-region fallback for failover and lower cold-starts.
-
Apply regional egress filters to limit cross-border copies.
Security hardening and privacy controls
-
Model access control: role-based keys and short-lived tokens.
-
Encryption: TLS for transit and AES-256 for data at rest.
-
Key management: use KMS with audit logging.
-
Consent and retention: explicit user consent, retain minimal samples, and auto-delete after a retention window.
-
Audit and watermarking: log synthesis events and consider inaudible watermarks for cloned voices.
Real-world case studies & benchmarks (anonymized)
IVR: move from batch to streaming TTS
-
Persistent stream between app and TTS engine (WebSocket/HTTP2).
-
Small jitter buffer in the client to smooth network variability.
-
Warm pools of model workers to avoid cold starts.
|
Metric
|
Before
|
After
|
|
p50 interaction latency
|
400 ms
|
80 ms
|
|
p95 interaction latency
|
1,200 ms
|
220 ms
|
Multilingual dubbing pipeline: quality vs speed
-
Hybrid flow: streaming for preview, offline pass for final files.
-
Use GPU inference for cloning and CPU autoscaling for bulk exports.
|
Metric
|
Before
|
After
|
|
wall-clock per 1 min source
|
8.2 min
|
1.3 min
|
|
average time-to-first-audio
|
4.5 s
|
1.1 s
|
FAQ — practical answers, next steps, and further reading
-
What latency targets should I set for voice agents in real-time synthesis?
For TTS latency optimization, pick targets based on interaction type. For conversational turn-taking, aim for 150 to 300 ms of end-to-end audio start. If you need lip sync or live musical timing, push below 100 ms. Track p50, p95, and p99 and design around your p95 for user-facing SLAs.
-
When should I move inference to the edge to reduce latency?
Move inference to the edge when network round-trip times add more jitter than your target, or when privacy and regulatory rules require local processing. Edge helps if sessions are geo-distributed and you can afford more infrastructure. If models are large and you need frequent updates, weigh deployment complexity and cost first.
-
How do I run reproducible latency tests for TTS pipelines?
1. Fix a canonical prompt set and audio config. 2. Test cold boot and warm sessions separately. 3. Measure p50, p95, p99, and tail jitter. 4. Inject controlled network conditions (latency, loss) and repeat. 5. Automate with CI and publish reproducible scripts in Node.js or Python.
-
How do pricing choices influence latency and cost trade-offs?
Higher-cost tiers or specialized low-latency endpoints typically buy faster inference and regional placement. Running on-prem or edge raises infra cost but cuts network delay. Choose a hybrid plan: cloud for scale, edge for critical low-latency paths. Recommended next steps: run a small benchmark, document p95 targets, and schedule an architecture review to align cost and latency goals.
 Discord
Discord YouTube
YouTube Tiktok
Tiktok Twitter
Twitter Facebook
Facebook